
grok-code-fast-1는 IDE 통합과 자동화된 코딩 에이전트를 구동하기 위해 설계된 xAI의 속도 중심, 비용 효율적인 에이전트형 코딩 모델입니다. 이 모델은 낮은 지연 시간, 에이전트형 동작(도구 호출, 단계별 추론 트레이스), 그리고 일상적인 개발자 워크플로에 적합한 간결한 비용 프로필을 강조합니다.
주요 기능(한눈에 보기)
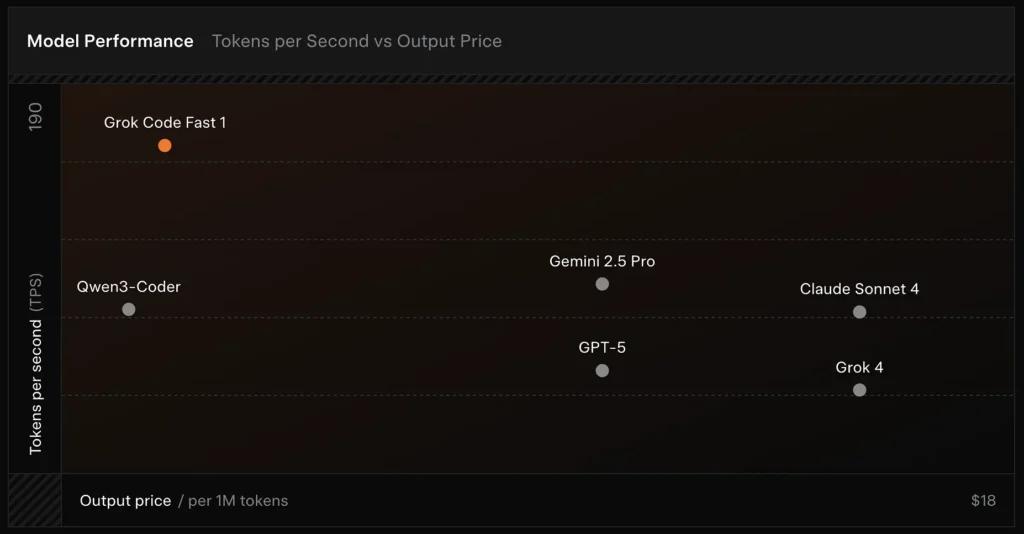
- 높은 처리량 / 낮은 지연: IDE 사용을 위한 매우 빠른 토큰 출력과 신속한 완료에 초점을 맞춤.
- 에이전트형 함수 호출 및 툴링: 다단계 코딩 에이전트를 위해 함수 호출과 외부 도구 오케스트레이션(테스트 실행, 린터, 파일 가져오기)을 지원.
- 대형 컨텍스트 윈도우: 대규모 코드베이스와 다중 파일 컨텍스트를 처리하도록 설계됨(마켓플레이스 어댑터에서 일부 공급자가 256k 컨텍스트를 지원한다고 명시).
- 가시적 추론/트레이스: 응답에 단계별 추론 트레이스를 포함해 에이전트의 의사결정을 점검하고 디버깅 가능하게 함.
기술 세부정보
아키텍처 및 학습: xAI에 따르면 grok-code-fast-1은 새 아키텍처로 처음부터 구축되었고, 프로그래밍 콘텐츠가 풍부한 사전 학습 코퍼스를 사용했으며, 이후 실제 고품质 풀리퀘스트/코드 데이터셋으로 후처리 학습을 거쳤습니다. 이 엔지니어링 파이프라인은 에이전트형 워크플로우에서 실용적 (IDE + 도구 사용) 이도록 설계되었습니다.
서빙 및 컨텍스트: grok-code-fast-1과 일반적인 사용 패턴은 스트리밍 출력, 함수 호출, 풍부한 컨텍스트 주입(파일 업로드/컬렉션)을 전제로 합니다. 여러 클라우드 마켓플레이스와 플랫폼 어댑터에서 이미 대형 컨텍스트 지원(일부 어댑터에서 256k 컨텍스트)을 명시하고 있습니다.
사용성 기능: 가시적인 추론 트레이스(모델이 계획/도구 사용을 표면화), 프롬프트 엔지니어링 가이드와 통합 예제, 초기 런칭 파트너 통합(예: GitHub Copilot, Cursor).
벤치마크 성능(평가 지표)
SWE-Bench-Verified: xAI는 SWE-Bench-Verified 서브셋에 대한 내부 하니스에서 70.8% 점수를 보고했습니다 — 소프트웨어 엔지니어링 모델 비교에 흔히 사용되는 벤치마크입니다. 최근 핸즈온 평가에서는 혼합 코딩 스위트에서 평균 인간 평가 ≈ 7.6을 기록했으며, 일부 고가치 모델(예: Gemini 2.5 Pro)과 경쟁적인 반면, 고난도 추론 작업에서는 Claude Opus 4와 xAI의 Grok 4 같은 대형 멀티모달/“최상위 추론” 모델에 다소 뒤처졌습니다. 벤치마크는 작업별 편차도 보이며: 일반적인 버그 수정과 간결한 코드 생성에는 뛰어나고, 일부 특수 분야나 라이브러리 특화 문제(Tailwind CSS 사례)에서는 약점을 보입니다.
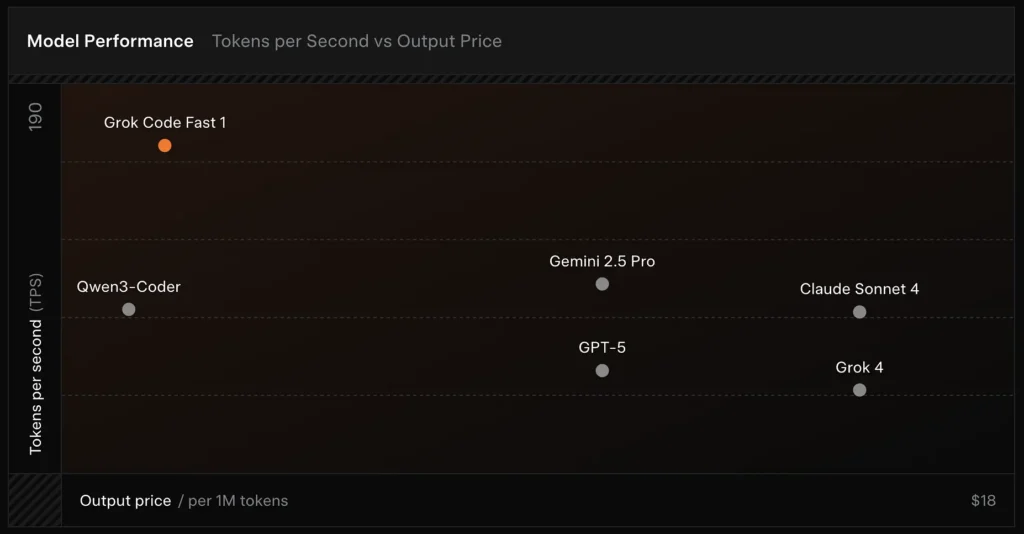
비교 :
- vs Grok 4: Grok-code-fast-1은 일부 절대적 정확도와 더 깊은 추론을 더 낮은 비용과 더 빠른 처리량으로 바꾸는 전략을 취합니다. Grok 4는 더 높은 역량 옵션으로 남습니다.
- vs Claude Opus / GPT-class: 해당 모델들은 복잡하고 창의적이거나 난도 높은 추론 작업에서 앞서는 경향이 있습니다. Grok-code-fast-1은 지연과 비용이 중요한 대량의 일상적 개발 작업에서 경쟁력이 높습니다.
한계 및 위험
현재까지 관찰된 실무적 한계:
- 도메인 공백: 특수 라이브러리나 비정형 문제에서 성능 저하가 나타날 수 있음(Tailwind CSS의 엣지 케이스 등).
- 추론 토큰 비용 트레이드오프: 모델이 내부 추론 토큰을 출력할 수 있으므로, 높은 에이전트성/장문의 추론은 출력 길이(및 비용)를 증가시킬 수 있음.
- 정확도 / 엣지 케이스: 일상 작업에는 강하지만, 새로운 알고리즘이나 적대적 문제에서 환각 또는 부정확한 코드를 생성할 수 있으며, 난도 높은 알고리즘 벤치마크에서는 최상위 추론 중심 모델 대비 열세일 수 있음.
일반적인 사용 사례
- IDE 지원 및 신속한 프로토타이핑: 빠른 완성, 증분 코드 작성, 대화형 디버깅.
- 자동화 에이전트 / 코드 워크플로우: 테스트 실행, 명령 수행, 파일 편집을 오케스트레이션하는 에이전트(예: CI 도우미, 봇 리뷰어).
- 일상 엔지니어링 작업: 코드 스켈레톤 생성, 리팩터링, 버그 분류 제안, 다중 파일 프로젝트 스캐폴딩 등에서 낮은 지연이 개발 흐름을 실질적으로 개선.
CometAPI에서 grok-code-fast-1 API를 호출하는 방법
grok-code-fast-1 API Pricing in CometAPI,공식 가격 대비 20% 할인:
- 입력 토큰: $0.16/ M tokens
- 출력 토큰: $2.0/ M tokens
필수 단계
- cometapi.com에 로그인합니다. 아직 사용자 계정이 없다면 먼저 등록하세요.
- 인터페이스의 액세스 자격 증명(API 키)을 획득합니다. 개인 센터의 API 토큰에서 “Add Token”을 클릭하고 토큰 키 sk-xxxxx를 받았다면 제출하세요.
사용 방법
- “
grok-code-fast-1” 엔드포인트를 선택해 API 요청을 보내고 요청 본문을 설정합니다. 요청 메서드와 본문은 웹사이트의 API 문서에서 확인할 수 있습니다. 편의를 위해 Apifox 테스트도 제공합니다. - <YOUR_API_KEY>를 계정의 실제 CometAPI 키로 바꿉니다.
- content 필드에 질문 또는 요청을 넣습니다 — 모델은 여기에 응답합니다.
- . API 응답을 처리하여 생성된 답변을 얻습니다.
CometAPI는 완전 호환 REST API를 제공합니다 — 원활한 마이그레이션을 위해. 주요 정보는 API 문서:
- Base URL: https://api.cometapi.com/v1/chat/completions
- Model Names: “
grok-code-fast-1“ - Authentication: Bearer 토큰 —
Authorization: Bearer YOUR_CometAPI_API_KEY헤더 - Content-Type:
application/json.
API 통합 및 예제
CometAPI를 통한 ChatCompletion 호출을 위한 Python 스니펫:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-code-fast-1's main features."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
See Also Grok 4