

W szybko ewoluującym krajobrazie AI GLM-5.2 od Z.ai (Zhipu AI) wyróżnia się jako potężny model o otwartych wagach, zoptymalizowany pod kątem agentowego kodowania, zadań długohoryzontowych i niezawodności produkcyjnej. Dzięki użytecznemu oknu kontekstu 1M tokenów, podwójnym trybom rozumowania (High i Max) oraz wysokiej wydajności przy ułamku kosztu zamkniętych modeli czołowych, szybko staje się podstawowym wyborem dla deweloperów budujących autonomicznych agentów, integracje z IDE i złożone przepływy inżynierii oprogramowania.
Niezależnie od tego, czy jesteś solo deweloperem tworzącym prototypy agentów, CTO oceniającym skalowanie pod kątem kosztów, czy menedżerem produktu AI integrującym rozumowanie zdolne do pracy multimodalnej w SaaS, opanowanie API GLM-5.2 odblokowuje znaczące korzyści.
Czym jest GLM-5.2?
GLM-5.2 to najnowszy flagowy model o otwartych wagach w architekturze Mixture-of-Experts (MoE) od Z.ai (Zhipu AI), wydany w połowie czerwca 2026 r. Dzięki około 753 miliardom łącznych parametrów (około 40B aktywnych na token), stabilnemu oknu kontekstu o wielkości 1 miliona tokenów, licencji MIT oraz wysokiej skuteczności w długohoryzontowym kodowaniu i zadaniach agentowych, pozycjonuje się jako konkurencyjna alternatywa dla zamkniętych modeli czołowych, takich jak GPT-5.5, Claude Opus 4.8 i warianty Gemini — przy znacznie niższych kosztach dla wielu zastosowań.
Architektura i specyfikacje techniczne GLM-5.2
GLM-5.2 rozwija rodzinę GLM o kluczowe usprawnienia dla pracy długohoryzontowej.
- Parametry: ~753B łącznie w projekcie MoE (aktywne parametry ~40B na token). Zapewnia to ogromną pojemność przy efektywnym wnioskowaniu.
- Okno kontekstu: 1 048 576 tokenów (1M). Maksymalna długość wyjścia zazwyczaj do 128K–131K tokenów.
- Precyzja: BF16 (z wariantami FP8 dla lżejszego wdrożenia).
- Kluczowa innowacja – IndexShare: Ponowne użycie jednego indeksatora w grupach warstw rzadkiej uwagi, redukujące FLOPs na token nawet o 2,9x przy kontekście 1M. Dzięki temu wnioskowanie na długim kontekście staje się opłacalne i szybkie.
- Tryby rozumowania: „High” (zrównoważony) i „Max” (najgłębszy, rekomendowany do kodowania). Myślenie można wyłączyć dla prostych zadań.
- Modalności: Głównie tekst/kod (brak potwierdzonego natywnego wsparcia wizji w wersji bazowej).
- Licencja: MIT — w pełni otwarty do pobrania, modyfikacji i użytku komercyjnego.
Ta otwartość i efektywność sprawiają, że GLM-5.2 jest idealny dla zespołów stawiających na prywatność danych, personalizację lub kontrolę kosztów.
GLM-5.2 vs GLM-5.1
| Obszar | GLM-5.1 | GLM-5.2 | Praktyczna różnica |
|---|---|---|---|
| Okno kontekstu | Około 200K na typowych hostowanych trasach | 1M | GLM-5.2 znacznie lepiej nadaje się do kontekstu całego projektu |
| Nakład rozumowania | Mniej elastyczne | High i Max | Lepsza kontrola kosztu, opóźnienia i jakości |
| Terminal Bench 2.1 | 63.5 w opublikowanej tabeli | 81.0 | Duża poprawa w zadaniach agentowych w terminalu |
| SWE-bench Pro | 58.4 | 62.1 | Umiarkowany, ale istotny wzrost na poziomie repozytoriów |
| FrontierSWE | 30.5 | 74.4 | Bardzo duża poprawa w długohoryzontowej inżynierii |
| Status otwartych wag | Otwarta rodzina GLM | Otwarte wydanie MIT | Podobna otwartość, silniejsza pozycja w długim kontekście |
Jeśli Twój obecny workflow na GLM-5.1 to głównie krótka rozmowa lub podstawowa generacja kodu, aktualizacja może nie zmienić wszystkiego. Jeśli jednak Twoja praca obejmuje duże repozytoria, wieloetapowe agentowe kodowanie lub długie wykonania zadań, GLM-5.2 jest znacznie bardziej adekwatnym modelem.
GLM-5.2 vs Claude Opus, GPT-5.5, Gemini i DeepSeek
Najczyściej porównać GLM-5.2 według typu zadania:
| Typ zadania | Pozycja GLM-5.2 |
|---|---|
| Długohoryzontowe kodowanie | Jedna z najsilniejszych opcji o otwartych wagach; blisko czołowych modeli zamkniętych na wybranych benchmarkach |
| Ogólne rozumowanie | Silny, ale nie zawsze przed najlepszymi modelami zamkniętymi |
| Użycie narzędzi | Silny wynik w MCP-Atlas i HLE-with-tools |
| Konkursy matematyczne | Bardzo wysoki wynik AIME 2026 w opublikowanych rezultatach |
| Wizja | Nie ten model; użyj modelu wizyjnego |
| Tania klasyfikacja na dużą skalę | Zwykle zbyt mocny; użyj mniejszego modelu |
| Self-hosting i personalizacja | Silniejsza opcja niż modele dostępne wyłącznie przez API |
Dla zespołów najlepszą odpowiedzią zwykle nie jest „zastąp każdy model GLM-5.2”. Lepsza odpowiedź to „kieruj GLM-5.2 do zadań, w których ma przewagę”. To jeden z powodów, dla których ujednolicony dostawca API, taki jak CometAPI, może być praktyczny. Umożliwia porównywanie i kierowanie modeli według charakteru pracy bez przebudowy wszystkich integracji.
Cennik: moc w rozsądnej cenie na skalę
GLM-5.2 oferuje przekonującą ekonomię, zwłaszcza dla zadań z dużą liczbą tokenów i długim kontekstem.
- Cennik API (przez Z.ai/OpenRouter/itp.): $1.40 / 1M tokenów wejściowych, $4.40 / 1M tokenów wyjściowych. Odczyt z pamięci podręcznej nawet za $0.26/1M na niektórych trasach.
- Subskrypcje planów GLM Coding (pełny dostęp, bez dopłat za 5.2):
- Lite: ~$10–12.60/mies. (lekka iteracja).
- Pro: ~$30/mies.
- Max/Team: Wyższe limity dla intensywnego użycia.
Przykład oszczędności kosztów: Dla długiej sesji agentowej z 500K kontekstu + wyjść, GLM-5.2 może być 4–5x tańszy niż odpowiedniki Claude, obsługując większe konteksty natywnie.
Rekomendacja CometAPI: Uzyskaj dostęp do GLM-5.2 (i 500+ innych modeli) przez ujednolicony endpoint zgodny z OpenAI w CometAPI w konkurencyjnych cenach. Jeden klucz, bez przywiązania do dostawcy, środki testowe po rejestracji. Idealne do porównania GLM-5.2 z Claude/GPT w produkcji. Odwiedź cometapi w celu bezproblemowej integracji.
Okno kontekstu 1M: wyróżniająca się cecha
Kontekst 1M jest „solidny” i w praktyce bezstratny dla pracy w skali projektu — daleko poza marketingową obietnicą. Umożliwia utrzymanie w kontekście całych średnich i dużych repozytoriów, redukując koszty streszczania i kumulację błędów u agentów.
Wskazówki efektywnego użycia:
- Użyj identyfikatora glm-5.2[1m].
- Ustaw odpowiednio maksymalną liczbę tokenów; monitoruj w produkcji.
- Łącz z narzędziami/MCP dla dynamicznego pobierania danych.
Wczesne testy potwierdzają stabilność powyżej 200K, co jest częstym punktem awarii innych modeli „long-context”.
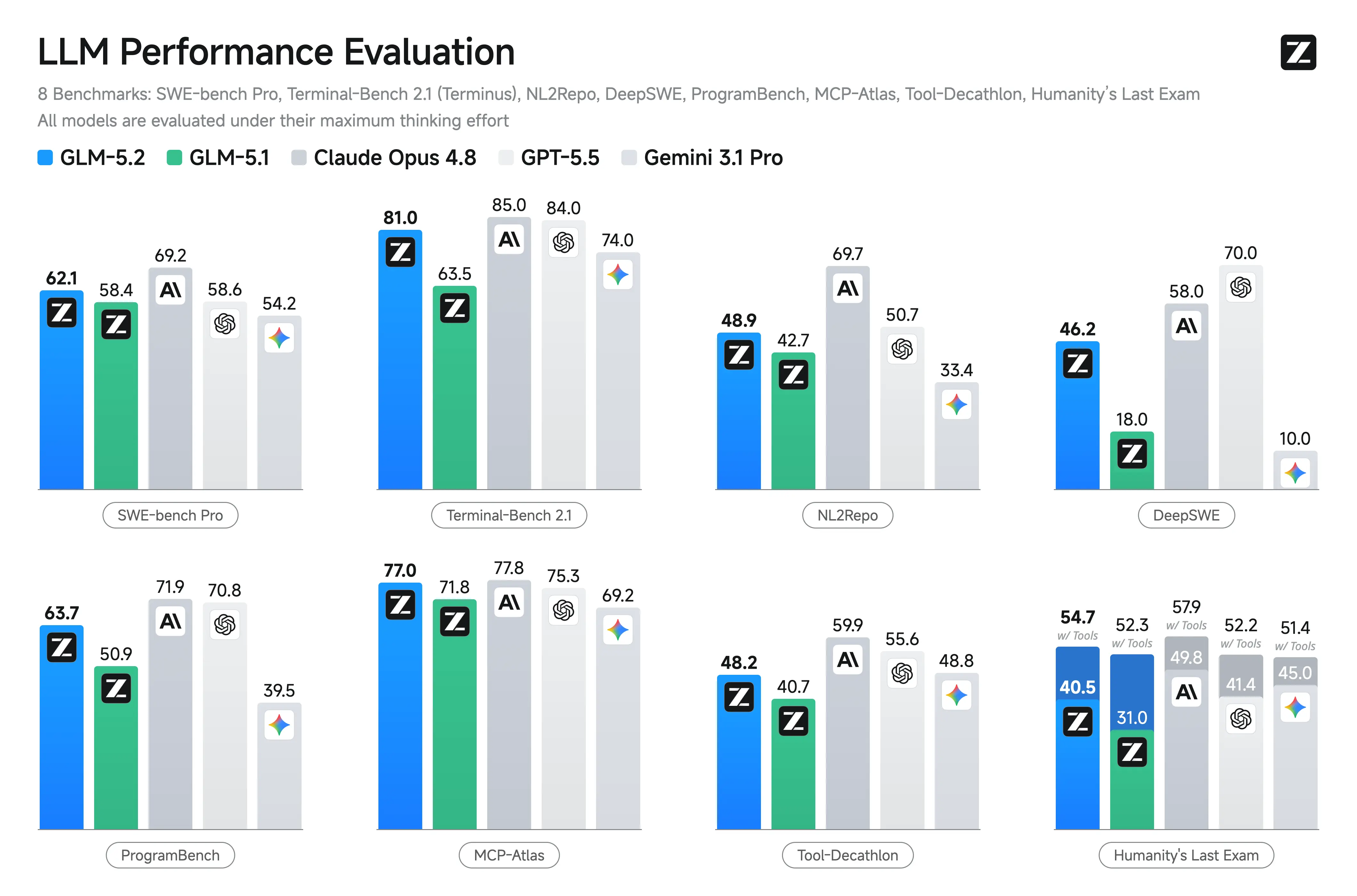
Wydajność bazowa i benchmarki
Z.ai i niezależne raporty podkreślają mocne strony GLM-5.2 w kodowaniu i scenariuszach agentowych. Wykazuje znaczące zyski względem GLM-5.1 i konkurencyjne wyniki wobec modeli zamkniętych w zadaniach długohoryzontowych.
Kluczowe zgłaszane benchmarki (Z.ai i agregaty stron trzecich):
- Terminal-Bench 2.1: 81.0 (wzrost z 62.0 GLM-5.1) — znakomity w operacjach terminalowych/agentowych.
- SWE-bench Pro: 62.1 (nieco przed GPT-5.5 z 58.6).
- MCP-Atlas: 77.0 (blisko Claude Opus 4.8).
- Humanity’s Last Exam (z narzędziami): 54.7.
Inne przewagi: Czołowy lub blisko czołówki wśród modeli otwartych na FrontierSWE, PostTrainBench, SWE-Marathon. Silny na AIME 2026 (~99.2) i GPQA-Diamond (91.2).
Opcje dostępu do API GLM-5.2
Istnieją dwa powszechne sposoby dostępu do GLM-5.2 z aplikacji.
Opcja 1: użyj Z.ai bezpośrednio
Bezpośrednią drogą jest użycie oficjalnego API Z.ai. To może być właściwy wybór, gdy zespół chce bezpośrednich relacji z dostawcą modelu, używa wyłącznie modeli Z.ai lub potrzebuje specyficznych dla dostawcy kontroli natychmiast po ich udostępnieniu.
Kompromis jest operacyjny. Jeśli Twój produkt używa wielu rodzin modeli, możesz potrzebować utrzymywać osobne konfiguracje SDK, rozliczenia, logikę failover, normalizację cen i standardy obserwowalności. Dla projektu badawczego może to być akceptowalne. Dla produkcyjnej platformy SaaS powierzchnia integracji szybko rośnie.
Opcja 2: użyj GLM-5.2 przez CometAPI
CometAPI zapewnia dostęp do GLM-5.2 przez ujednoliconą bramę API. Praktyczna korzyść polega na tym, że deweloperzy mogą wywoływać różne modele AI przez jeden interfejs zgodny z OpenAI zamiast budować osobną integrację dla każdego dostawcy. Zachowujesz kod bliski wzorcowi SDK OpenAI, ustawiasz nazwę modelu na glm-5.2 i kierujesz zapytania przez CometAPI.
To przydatne dla startupów i zespołów produktowych, które chcą:
- Testować GLM-5.2 wobec innych modeli bez przebudowy backendu
- Utrzymać jeden klucz API i jedną warstwę rozliczeń dla wielu modeli
- Szybciej przejść od benchmarku przez prototyp do produkcji
- Wdrożyć strategie fallbacku lub routingu modeli
- Porównywać koszt i jakość między dostawcami
- Korzystać z znajomych wzorców zapytań w stylu OpenAI
Zarejestruj się na CometAPI.com, aby uzyskać natychmiastowe środki testowe i endpointy zgodne z OpenAI, które ukrywają różnice między dostawcami.
- Uzyskaj swój klucz API.
- Ustaw zmienne środowiskowe (najlepsza praktyka bezpieczeństwa):
export GLM_API_KEY="your_key_here"
export BASE_URL="https://api.cometapi.com/v1" # or direct Z.ai endpoint
Wykonanie pierwszego wywołania API GLM-5.2
Przykład cURL (szybki test):
bash
curl https://api.z.ai/api/paas/v4/chat/completions \
-H "Authorization: Bearer $GLM_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5.2",
"messages": [
{"role": "system", "content": "You are an expert full-stack engineer."},
{"role": "user", "content": "Write a FastAPI endpoint for user authentication with JWT."}
],
"temperature": 0.7,
"max_tokens": 2048
}'
Typowe przypadki użycia GLM-5.2
GLM-5.2 to mocny kandydat do przepływów, w których łączą się długi kontekst, rozumowanie i użycie narzędzi.
| Przypadek użycia | Przykładowa implementacja | Dlaczego GLM-5.2 może pasować |
|---|---|---|
| Asystent deweloperski | Analiza zgłoszeń błędów, fragmentów kodu, logów i testów | Wymaga rozumowania w oparciu o kontekst techniczny |
| Analiza dokumentów | Przegląd umów, polityk, roszczeń lub raportów | Długie wejścia i strukturyzowana ekstrakcja |
| Agent badawczy | Czytanie źródeł, porównywanie twierdzeń, tworzenie podsumowań | Korzyść z długiego kontekstu i dyscypliny cytowania |
| Copilot wsparcia klienta | Połączenie historii zgłoszeń, dokumentacji, danych konta i polityk | Potrzebne pobieranie + wywoływanie narzędzi |
| Asystent PM ds. AI | Synteza feedbacku, specyfikacji, danych użycia i notatek roadmapy | Długi kontekst i rozumowanie biznesowe |
| Analiza bezpieczeństwa | Przegląd raportów incydentów, alertów i planów remediacji | Wymaga uważnego, wieloetapowego rozumowania |
| Inżynieria sprzedaży | Generowanie technicznych odpowiedzi z dokumentacji i wymagań | Przydatne w złożonych cyklach sprzedaży B2B |
Wspólnym wzorcem nie jest „chatbot”. Wspólnym wzorcem jest kompresja przepływu pracy. GLM-5.2 może skrócić czas między surową informacją a użyteczną decyzją.
Kto powinien używać GLM-5.2?
GLM-5.2 dobrze pasuje do:
- Deweloperów tworzących narzędzia do kodowania AI.
- Firm SaaS dodających asystentów świadomych repozytoriów.
- CTO oceniających otwarte alternatywy dla zamkniętych modeli kodujących.
- Menedżerów produktu AI testujących przepływy z długim kontekstem.
- Przedsiębiorstw planujących przyszły self-hosting lub większą kontrolę nad danymi.
- Platform deweloperskich potrzebujących opcjonalności modeli.
- Zespołów pracujących z dużymi dokumentami technicznymi, SDK lub bazami kodu.
Jest szczególnie atrakcyjny, gdy porażka zadania jest kosztowna. Jeśli błąd modelu powoduje zepsute buildy, złe migracje lub stratę czasu inżynierskiego, koszt użycia mocniejszego modelu szybko się zwraca.
Kiedy nie używać GLM-5.2
Nie traktuj GLM-5.2 jako domyślnego dla:
- Krótkich i powtarzalnych zadań klasyfikacyjnych.
- Prostych przeróbek tekstu.
- Rozumienia obrazów lub zrzutów ekranu.
- Autouzupełniania o bardzo niskim opóźnieniu, gdzie liczą się milisekundy.
- Przepływów, w których mniejszy model już działa dobrze.
- Produktów, które nie tolerują długotrwałej generacji.
Celem nie jest czczenie największego okna kontekstu. Celem jest rozwiązanie zadania z odpowiednim profilem jakości, kosztu i opóźnienia.
Werdykt końcowy
GLM-5.2 to jedno z najważniejszych otwartych wydań modeli AI dla zespołów inżynierii oprogramowania w 2026 r. Połączenie kontekstu 1M, mocnych benchmarków w kodowaniu, trybów rozumowania High i Max, wsparcia wywoływania funkcji oraz licencji MIT czyni go poważną opcją dla agentów kodujących i długohoryzontowych przepływów AI.
Dla zespołów chcących szybko go sprawdzić, CometAPI to pragmatyczna warstwa dostępu. Możesz wywoływać GLM-5.2 przez endpoint zgodny z OpenAI, porównywać go z innymi wiodącymi modelami, monitorować użycie i zbudować strategię routingu bez przebudowy całego stosu wokół jednego dostawcy. Zacznij od małej prywatnej ewaluacji, zmierz koszt na zadanie rozwiązane i wdrażaj GLM-5.2 w produkcji tylko tam, gdzie jego przewagi długiego kontekstu wyraźnie się zwracają.
Gotowy, by przetestować GLM-5.2 w swojej aplikacji? Poznaj GLM-5.2 na CometAPI, utwórz klucz API i uruchom pierwsze żądanie zgodne z OpenAI w kilka minut. Użyj go do realnego zadania na repozytorium, nie zabawkowego promptu, i porównaj wynik z obecną pulą modeli.