

GPT-5.2 是 OpenAI 在 2025 年 12 月發布的 GPT-5 系列小版本更新:這是一個旗艦級多模態模型家族(文字 + 視覺 + 工具),針對「專業知識工作、長上下文推理、代理式工具使用、與軟體工程」進行調校。OpenAI 將 GPT-5.2 定位為迄今最強的 GPT-5 系列模型,並表示該版本著重於可靠的多步推理、處理超大文檔、以及更完善的安全與政策合規;此次發佈包含三個面向用戶的變體 —— Instant、Thinking、Pro —— 並首先向付費 ChatGPT 訂閱者與 API 客戶開放。
什麼是 GPT-5.2,為何重要?
GPT-5.2 是 OpenAI 的 GPT-5 家族最新成員 —— 一個為縮短「單輪對話助理」與「必須在長文檔中推理、調用工具、解讀圖像、並可靠執行多步工作流程」之間差距而設計的「前沿」模型系列。OpenAI 將 5.2 定位為其專業知識工作領域迄今最強版本:在內部基準(尤其是一個針對知識工作的全新 GDPval 基準)上創下新高,在軟體工程基準上展現更強的編碼能力,並大幅提升長上下文與視覺能力。
在實務層面,GPT-5.2 不僅僅是「更大的聊天模型」。它是一個由三個調校變體(Instant、Thinking、Pro)組成的家族,在延遲、推理深度與成本上進行取捨 —— 結合 OpenAI 的 API 與 ChatGPT 路由,可用於執行長時間研究任務、構建會調用外部工具的代理、解讀複雜圖像與圖表、並以比以往更高保真度生成可投入生產的程式碼。該模型支援超大上下文窗口(OpenAI 文檔列出旗艦模型具備 400,000 Token 的上下文窗口與 128,000 的最大輸出限制)、新的 API 功能以顯式控制推理投入程度,以及「代理式」工具調用行為。
GPT-5.2 的 5 大核心能力升級
1) GPT-5.2 在多步邏輯與數學方面是否更強?
GPT-5.2 帶來更銳利的多步推理,並在數學與結構化問題求解上有顯著提升。OpenAI 表示他們新增了對推理投入的更細粒度控制(新增如 xhigh 等級)、設計了「推理 Token」支援,並調校模型在更長的內部推理鏈條上維持連貫的思維鏈。像 FrontierMath 與 ARC-AGI 類測試等基準對比 GPT-5.1 顯示出實質增益;在科學與金融工作流程等領域的專用基準上,亦有更大幅度的優勢。簡言之:GPT-5.2 在需要時會「想得更久」,能更穩定地處理更複雜的符號/數學任務。

| RC-AGI-1 (Verified) 抽象推理 | 86.2% | 72.8% |
|---|---|---|
| ARC-AGI-2 (Verified) 抽象推理 | 52.9% | 17.6% |
GPT-5.2 Thinking 在多項高階科學與數學推理測試中創下紀錄:
- GPQA Diamond Science Quiz:92.4%(Pro 版本 93.2%)
- ARC-AGI-1 抽象推理:86.2%(首個突破 90% 門檻的模型)
- ARC-AGI-2 高階推理:52.9%,為 Thinking Chain 模型創新高
- FrontierMath 高等數學測試:40.3%,遠超前代;
- HMMT 數學競賽題:99.4%
- AIME 數學測試:100% 完整解法
此外,GPT-5.2 Pro(High)在 ARC-AGI-2 上達到最先進水準,以每個任務 $15.72 的成本獲得 54.2% 的分數!超越所有其他模型。
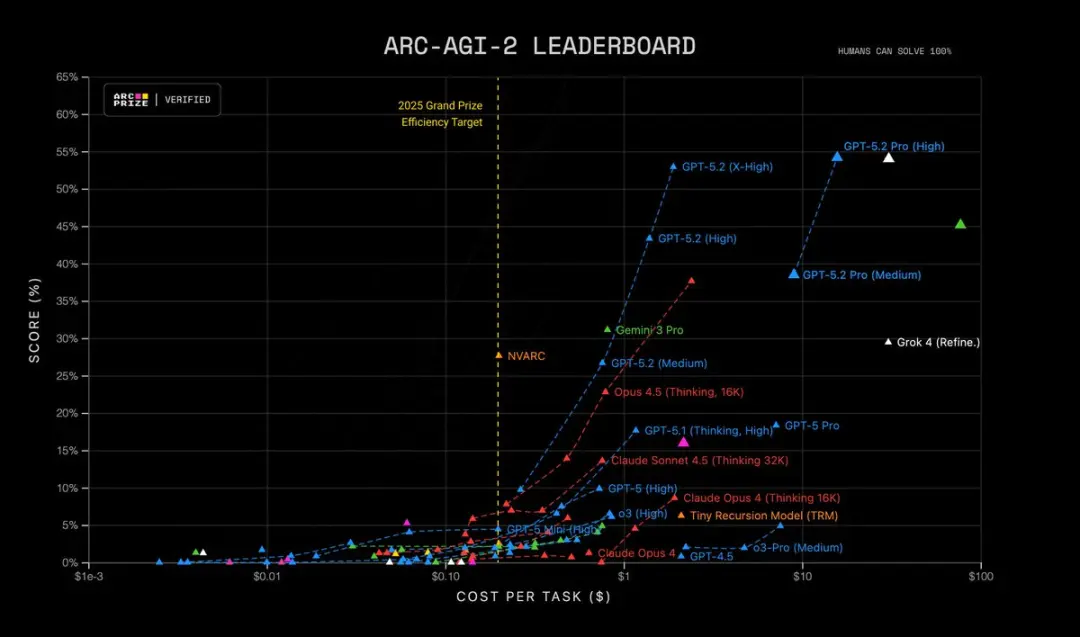
重要性:許多真實世界任務 —— 金融建模、實驗設計、需要形式化推理的程式合成 —— 都受制於模型能否將多個正確步驟串聯起來。GPT-5.2 降低了「幻覺步驟」並在你要求其展示過程時產生更穩定的中間推理軌跡。
2) 長文本理解與跨文檔推理有何改進?
長上下文理解是重點改進之一。GPT-5.2 的底層模型支援 400k Token 的上下文窗口,且更重要的是:當關鍵內容位於極深上下文時,依然能維持較高的準確度。GDPval 是一套涵蓋 44 種職能的「明確規範的知識工作」任務集,GPT-5.2 Thinking 在其中大比例任務上已達到或超越人類專家的表現。獨立報導也確認,該模型在跨多文檔的信息保持與綜合上遠勝以往。這對盡職調查、法律摘要、文獻綜述、與代碼庫理解等任務是實用且顯著的前進。
GPT-5.2 可處理長達 256,000 Token 的上下文(約 200+ 頁文檔)。此外,在「OpenAI MRCRv2」長文本理解測試中,GPT-5.2 Thinking 的準確率接近 100%。
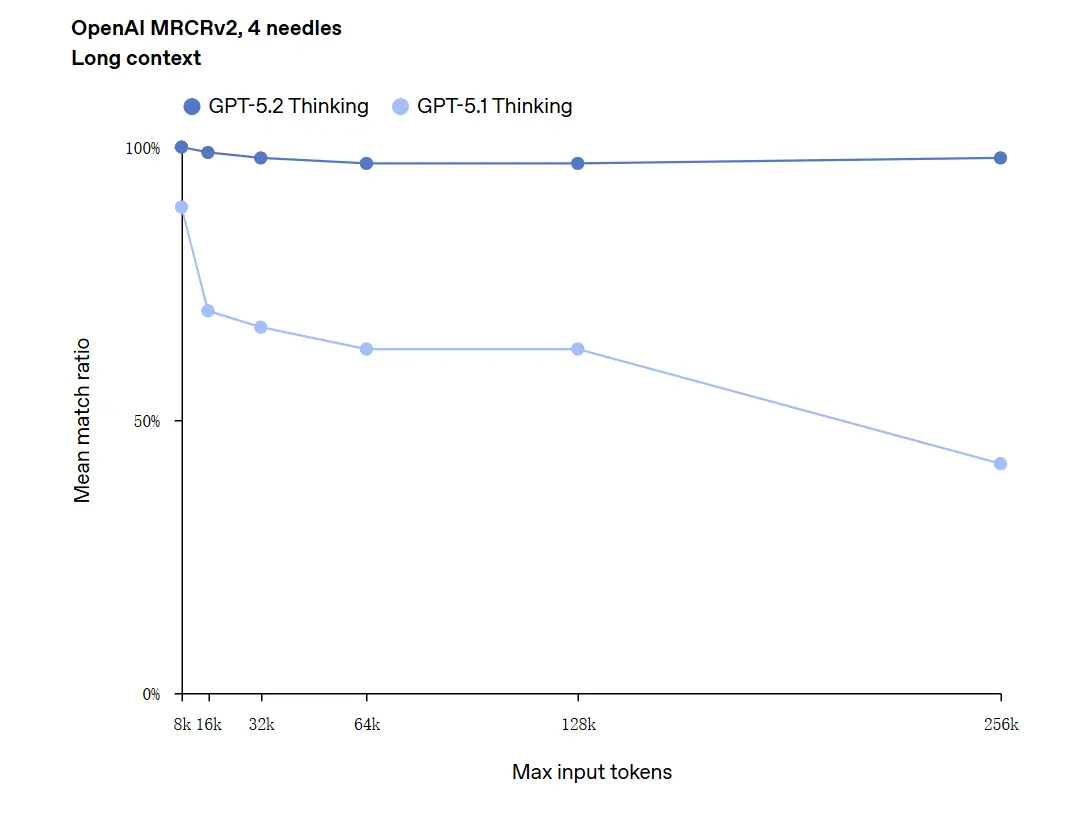
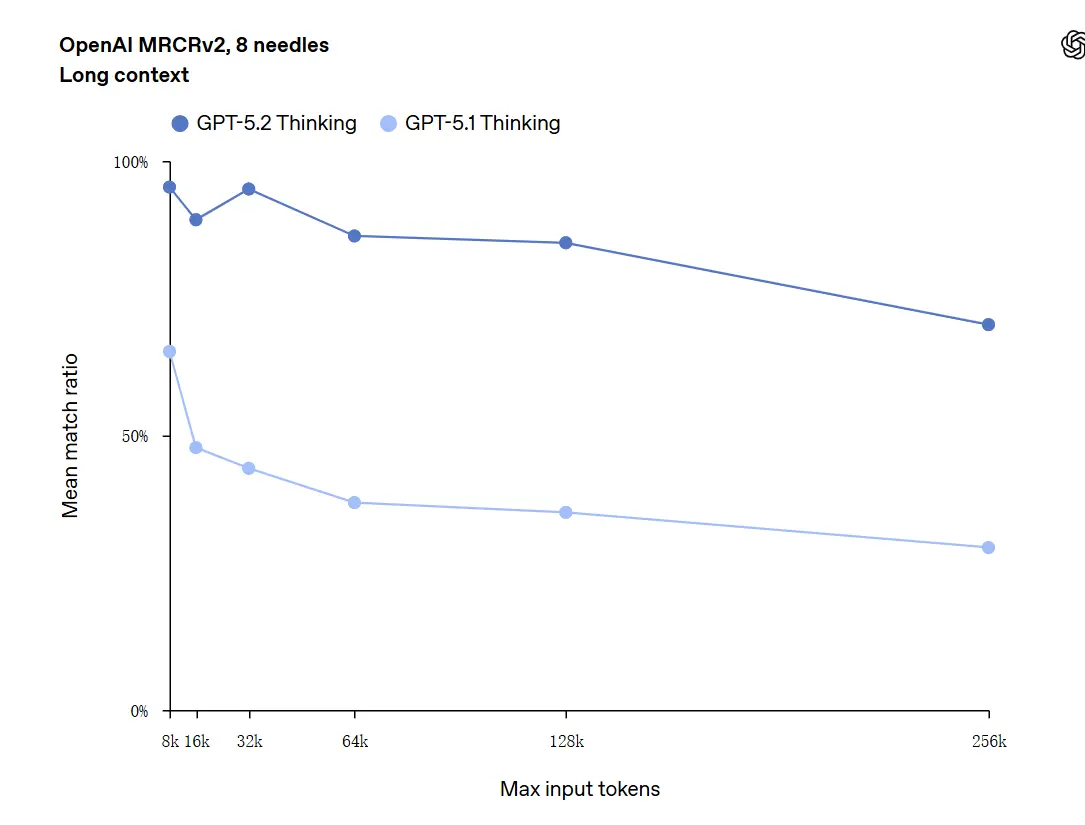
關於「100% 準確率」的說明:OpenAI 將此描述為在狹窄的微型任務上「接近 100%」;更嚴謹的表述是「在許多任務上達到或超越人類專家水準的最先進表現」,而非在所有使用情境中完美無瑕。基準顯示大幅增益,但並非普遍完美。
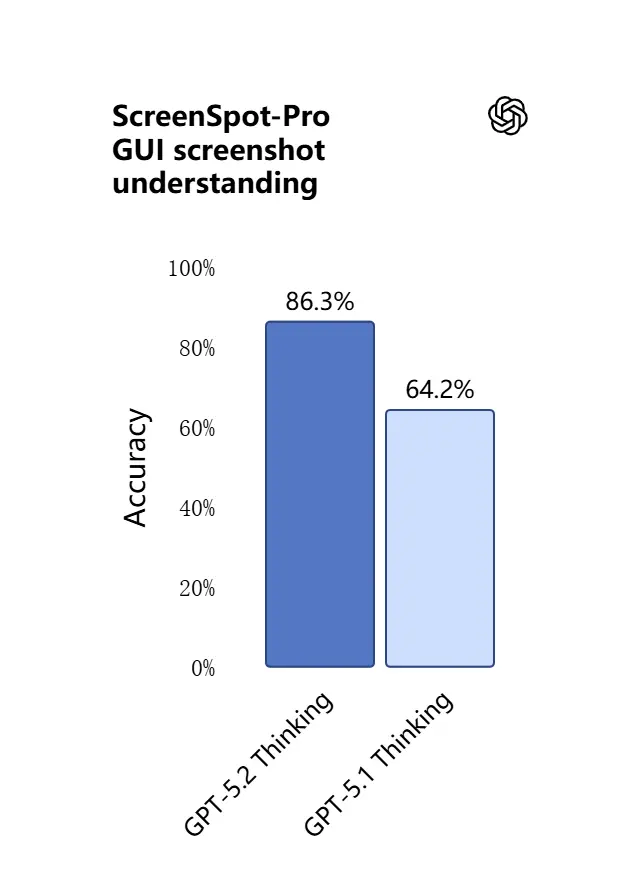
3) 視覺理解與多模態推理有何新進展?
GPT-5.2 的視覺能力更銳利、更實用。模型更擅長解讀截圖、讀取圖表與表格、識別 UI 元素,並能將視覺輸入與長文本上下文結合。這不只是圖像描述:GPT-5.2 能從圖像中抽取結構化資料(例如 PDF 中的表格)、解釋圖形,並以支持下游工具動作的方式對圖解進行推理(例如從拍攝的報告生成試算表)。
.webp)
實際效果:團隊可以將完整簡報、掃描研究報告或大量圖片的文檔直接輸入模型,請其做跨文檔綜合 —— 大幅減少手動抽取的工作量。
4) 工具調用與任務執行有何變化?
GPT-5.2 更進一步邁向代理式行為:它更擅長規劃多步任務、決定何時調用外部工具,並執行一系列 API/工具調用,以端到端完成工作。「代理式工具調用」得到改進 —— 模型會提出計畫、調用工具(資料庫、計算、檔案系統、瀏覽器、代碼執行器),並更可靠地將結果綜合為最終交付。API 引入了路由與安全控制(允許工具清單、工具腳手架),ChatGPT 的介面也可自動將請求路由至合適的 5.2 變體(Instant vs Thinking)。
GPT-5.2 在 Tau2-Bench Telecom 基準上獲得 98.7% 的成績,展現其在複雜多輪任務中的成熟工具調用能力。
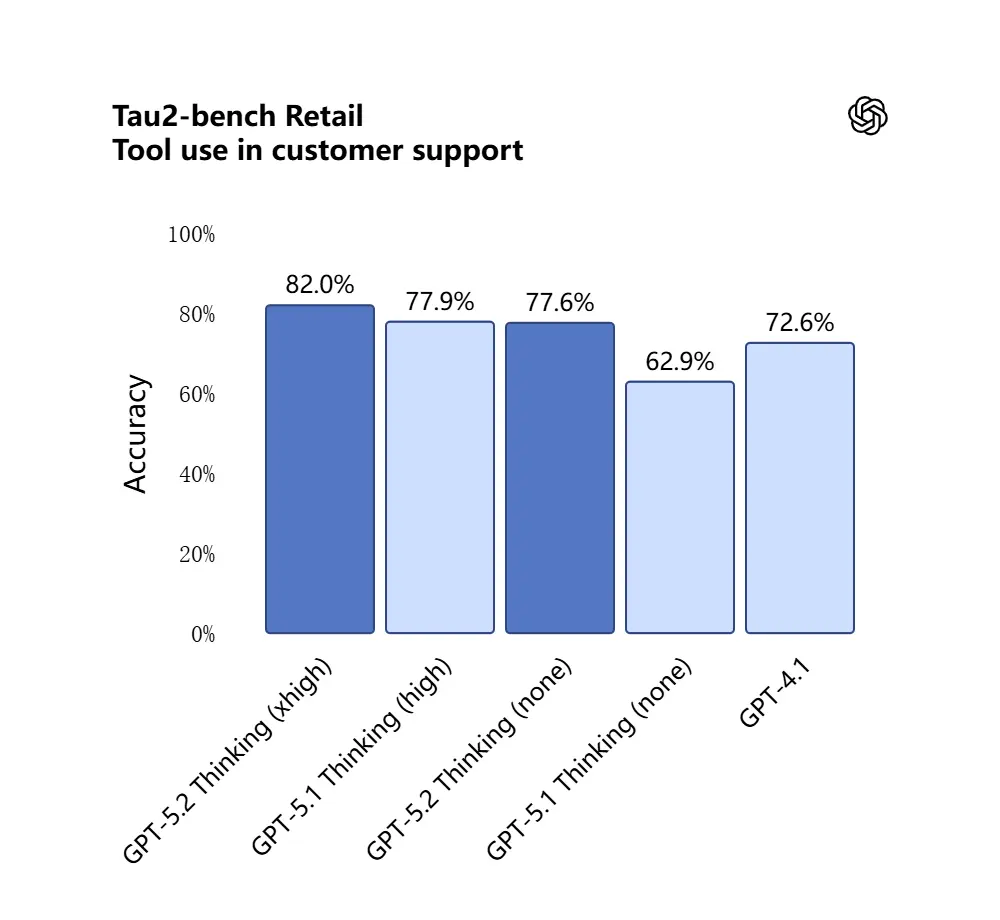
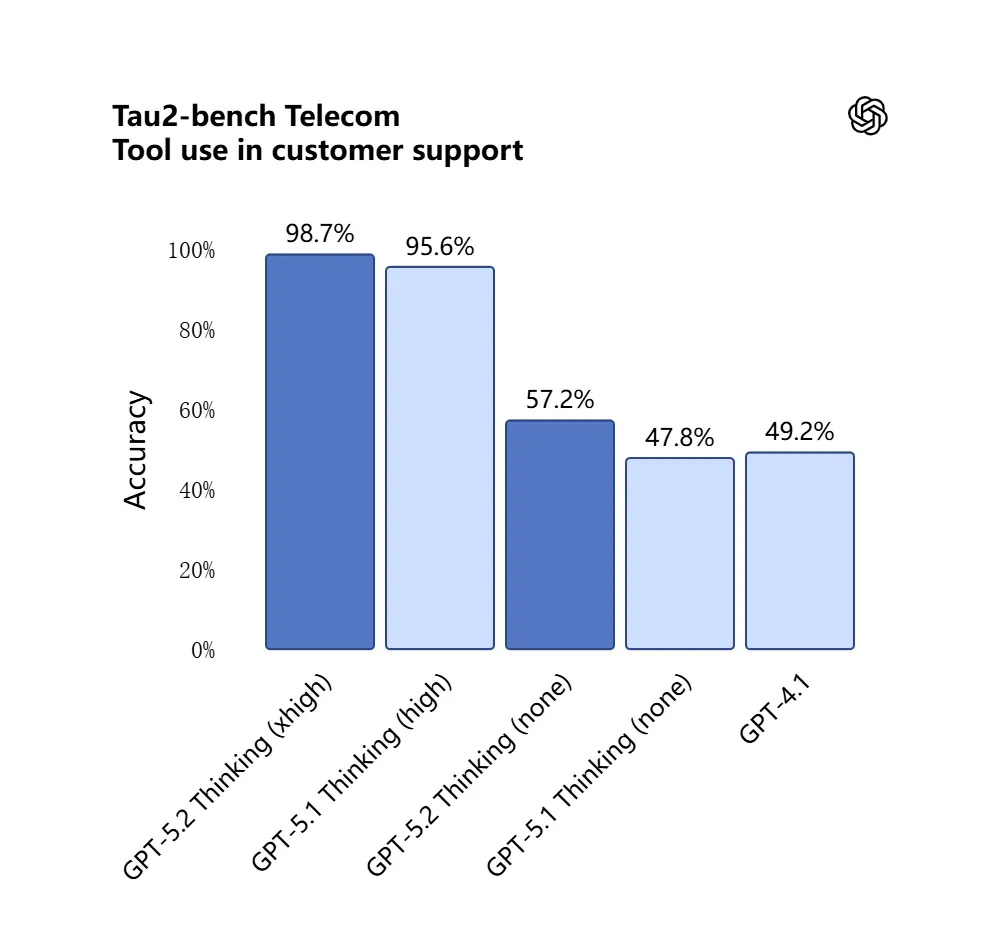
重要性:這使 GPT-5.2 作為工作流程中的自動助理更有用,例如「攝入這些合約、抽取條款、更新試算表、並撰寫總結郵件」—— 過去需要仔細編排的任務,如今可更自治地完成。
5) 程式設計能力進化
GPT-5.2 在軟體工程任務上明顯更強:它能生成更完整的模組、更可靠地生成與運行測試、更好地理解複雜專案的依賴關係圖,且更不容易「偷懶式編碼」(跳過樣板或未將模組正確接線)。在產業級編碼基準(如 SWE-bench Pro 等)上,GPT-5.2 創下新高。對將 LLM 作為結對程式設計助手的團隊而言,這種提升能減少生成後所需的人工驗證與返工。
在 SWE-Bench Pro 測試(真實世界產業級軟體工程任務)中,GPT-5.2 Thinking 的得分提升至 55.6%,同時在 SWE-Bench Verified 測試中也達到新的 80% 高點。
_Software%20engineering.webp)
在實際應用中,這意味著:
- 生產環境代碼的自動除錯更穩定;
- 支援多語言編程(不僅限於 Python);
- 具備獨立完成端到端修復任務的能力。
GPT-5.2 與 GPT-5.1 有何不同?
簡短回答:GPT-5.2 是一次迭代但實質的升級。它保留了 GPT-5 家族的架構與多模態基礎,但在四個實用面向上推進:
- 推理的深度與一致性。 5.2 引入更高的推理投入等級與更好的多步鏈接;5.1 先前已改進推理,但 5.2 進一步提升了複雜數學與多階段邏輯的上限。
- 長上下文可靠性。 兩個版本都擴展了上下文,但 5.2 調校以在極長輸入中維持準確度(OpenAI 聲稱在數十萬 Token 的範圍內有更好的保持)。
- 視覺 + 多模態保真度。 5.2 改善了圖像與文本之間的交叉引用 —— 例如讀取圖表並將數據整合到試算表中 —— 在任務層面展現更高的準確性。
- 代理式工具行為與 API 功能。 5.2 在 API 中提供新的推理投入參數(
xhigh)與上下文壓縮功能,OpenAI 也優化了 ChatGPT 的路由邏輯,使介面可自動選擇最佳變體。 - 更少錯誤、更高穩定性:GPT-5.2 將其「illusion rate」(錯誤應答率)降低了 38%。在研究、寫作與分析問題上更可靠,減少「捏造事實」的情況。在複雜任務中,其結構化輸出更清晰、邏輯更穩定。同時,模型在心理健康相關任務上的回應安全性顯著提升。它在心理健康、自我傷害、自殺、情感依賴等敏感情境中表現更穩健。
在系統評估中,GPT-5.2 Instant 在「心理健康支持」任務上獲得 0.995(滿分 1.0),顯著高於 GPT-5.1(0.883)。
以量化而言,OpenAI 發布的基準顯示在 GDPval、數學基準(FrontierMath)、與軟體工程評測上有可測量的提升。GPT-5.2 在初級投行試算表任務中也比 GPT-5.1 提高了若干個百分點。
GPT-5.2 免費嗎 —— 需要多少費用?
我可以免費使用 GPT-5.2 嗎?
OpenAI 優先向付費的 ChatGPT 計畫與 API 使用者推出 GPT-5.2。依照以往慣例,OpenAI 會將最快/最強的模型保留在付費層,較輕量的變體則可能稍晚更廣泛開放;對於 5.2,公司表示將從付費方案(Plus、Pro、Business、Enterprise)開始推出,並向開發者開放 API。這意味著立即的免費存取有限:免費層可能在擴大推出後,獲得降級或路由到較輕子變體的存取。
好消息是 CometAPI 現已整合 GPT-5.2,且目前有聖誕優惠。你現在可以透過 CometAPI 使用 GPT-5.2;Playground 允許你自由與 GPT-5.2 互動,開發者也可使用 GPT-5.2 API(CometAPI 的定價為 OpenAI 的 20%)來構建工作流程。
透過 API(開發/生產)需要多少費用?
API 使用按 Token 計費。OpenAI 在發布時公布的平台定價如下(CometAPI 的定價為 OpenAI 的 20%):
- GPT-5.2(標準聊天) —— 每 1M 輸入 Token $1.75、每 1M 輸出 Token $14(快取輸入可享折扣)。
- GPT-5.2 Pro(旗艦) —— 每 1M 輸入 Token $21、每 1M 輸出 Token $168(因面向高準確度、計算量大的工作負載而顯著更高)。
- 作為對比,GPT-5.1 更便宜(例如每 1M Token:輸入 $1.25 / 輸出 $10)。
解讀: 相較前代,API 成本上升;價格信號表明 5.2 的高階推理與長上下文表現被定價為獨立產品層。對於生產系統,成本很大程度取決於輸入/輸出的 Token 數量與快取輸入的重用頻率(快取輸入可獲大幅折扣)。
實務上意味著什麼
- 對於透過 ChatGPT 介面的日常使用,每月訂閱方案(Plus、Pro、Business、Enterprise)是主要途徑。隨著 5.2 發布,ChatGPT 訂閱層級的價格未變(OpenAI 通常在模型供應變動時保持方案價格穩定)。
- 對於生產與開發者使用,需為 Token 成本預算。若你的應用串流大量長回覆或處理長文檔,輸出 Token 的價格(Thinking 為 $14 / 1M Token)將主導成本,除非你謹慎使用輸入快取並重用輸出。
GPT-5.2 Instant vs GPT-5.2 Thinking vs GPT-5.2 Pro
OpenAI 針對不同使用情境,推出三個目的導向的變體:Instant、Thinking、Pro:
- GPT-5.2 Instant: 速度快、成本效率高,面向日常工作 —— FAQ、操作指南、翻譯、快速起草。較低延遲;適合初稿與簡單流程。
- GPT-5.2 Thinking: 面向持續性工作給出更深入、更高品質回應 —— 長文檔摘要、多步規劃、詳細代碼審查。延遲與品質平衡;專業任務的「主力」。
- GPT-5.2 Pro: 最高品質與可信度。較慢且成本更高;適用於困難、高風險任務(複雜工程、法律綜合、高價值決策),以及需要
xhigh推理投入的情境。
比較表
| 功能 / 指標 | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|
| 預期用途 | 日常任務、快速起草 | 深度分析、長文檔 | 最高品質、複雜問題 |
| 延遲 | 最低 | 中等 | 最高 |
| 推理強度 | 標準 | 高 | xHigh 可用 |
| 最適用於 | FAQ、教學、翻譯、短提示 | 摘要、規劃、試算表、編碼任務 | 複雜工程、法律綜合、研究 |
| API 名稱示例 | gpt-5.2-chat-latest | gpt-5.2 | gpt-5.2-pro |
| 輸入 Token 價格(API) | $1.75 / 1M | $1.75 / 1M | $21 / 1M |
| 輸出 Token 價格(API) | $14 / 1M | $14 / 1M | $168 / 1M |
| 可用性(ChatGPT) | 逐步推出;先付費方案再更廣泛 | 逐步向付費方案推出 | Pro 用戶 / 企業(付費) |
| 典型用例 | 撰寫郵件、少量程式碼片段 | 構建多表財務模型、長篇報告問答 | 稽核代碼庫、生成生產級系統設計 |
誰適合使用 GPT-5.2?
GPT-5.2 面向廣泛使用者群。以下為基於角色的建議:
企業與產品團隊
若你構建知識工作產品(研究助理、合約審查、分析管線、或開發者工具),GPT-5.2 的長上下文與代理能力可顯著降低整合複雜度。需要穩健文檔理解、自動化報告、或智慧 Copilot 的企業將會受益於 Thinking/Pro。Microsoft 與其他平台夥伴已將 5.2 整合至生產力套件(如 Microsoft 365 Copilot)。
開發者與工程團隊
欲將 LLM 作為結對程式設計助手或自動化代碼生成/測試的團隊,將從 5.2 更高的程式設計保真度中獲益。API 訪問(使用 thinking 或 pro 模式)在 400k Token 上下文窗口的加持下,能對大型代碼庫進行更深入的綜合。使用 Pro 時 API 成本會更高,但在複雜系統上減少的手動除錯與審核可能足以抵消成本。
研究人員與重數據分析師
若你經常綜合文獻、解析長技術報告、或需要模型輔助的實驗設計,GPT-5.2 的長上下文與數學提升可加速工作流程。為了可重現的研究,建議結合審慎的提示工程與驗證步驟。
中小企業與高端用戶
ChatGPT Plus(與 Pro 供高端用戶)將獲得對 5.2 變體的路由存取;這使小型團隊無需建立 API 整合即可使用高階自動化與高品質輸出。對於需要更佳文檔摘要或投影片製作的非技術用戶,GPT-5.2 帶來明顯實用價值。
給開發與運維人員的實務備忘
值得關注的 API 功能
reasoning.effort等級(例如medium、high、xhigh)允許你告訴模型在內部推理上投入多少計算;用這個在單次請求層面權衡延遲與準確度。- 上下文壓縮(Context compaction):API 提供壓縮與緊縮歷史的工具,以保留真正相關的內容。當你需要在長對話鏈中控制有效 Token 用量時,這尤為關鍵。
- 工具腳手架與允許工具控制:生產系統應明確白名單可調用的工具,並記錄工具調用以便稽核。
成本控制技巧
- 快取常用的文檔嵌入,對相同語料的重複查詢使用快取輸入(平台對快取輸入提供大幅折扣)。OpenAI 的平台定價對快取輸入有明顯優惠。
- 將探索性/低價值查詢路由到 Instant,將 Thinking/Pro 留給批次任務或最後定稿。
- 在預估 API 成本時謹慎估算 Token 用量(輸入 + 輸出),因為長輸出會成倍增加成本。
底線 —— 是否該升級到 GPT-5.2?
如果你的工作依賴長文檔推理、跨文檔綜合、多模態解讀(圖像 + 文字)、或構建會調用工具的代理,GPT-5.2 是明確的升級:它提升實際準確度,並降低整合工作量。若你主要運行高頻、低延遲的聊天機器人或預算極為受限的應用,Instant(或更早的模型)可能仍是合理選擇。
GPT-5.2 代表從「更好的聊天」轉向「更專業的助理」的刻意變化:投入更多計算、提供更高能力、採用更高費用層級 —— 但對能利用可靠長上下文、更佳數學/推理、圖像理解、與代理式工具執行的團隊而言,也帶來實打實的生產力提升。
開始使用前,先在 Playground 體驗 GPT-5.2 模型(GPT-5.2;GPT-5.2 pro、GPT-5.2 chat)的能力,並查閱 API guide 取得詳細指引。訪問前請確認已登入 CometAPI 並取得 API Key。CometAPI 以遠低於官方的價格,助你快速整合。
準備好了嗎?→ gpt-5.2 模型免費試用 !