
grok-code-fast-1 là mô hình lập trình mang tính tác nhân tập trung vào tốc độ và hiệu quả chi phí của xAI, được thiết kế để vận hành các tích hợp IDE và tác nhân mã hóa tự động. Mô hình nhấn mạnh độ trễ thấp, hành vi mang tính tác nhân (gọi công cụ, vệt lập luận theo từng bước), và cấu hình chi phí gọn cho quy trình làm việc hàng ngày của nhà phát triển.
Tính năng chính (tổng quan nhanh)
- Thông lượng cao / độ trễ thấp: tập trung vào tốc độ sinh token rất nhanh và hoàn thành nhanh cho mục đích dùng trong IDE.
- Gọi hàm mang tính tác nhân & công cụ: hỗ trợ gọi hàm và điều phối công cụ bên ngoài (chạy kiểm thử, linters, lấy tệp) để kích hoạt tác nhân mã hóa nhiều bước.
- Cửa sổ ngữ cảnh lớn: được thiết kế để xử lý các codebase lớn và ngữ cảnh đa tệp (một số nhà cung cấp liệt kê cửa sổ ngữ cảnh 256k trong các adapter marketplace).
- Lập luận/trace hiển thị: phản hồi có thể bao gồm dấu vết lập luận theo từng bước, giúp quyết định của tác nhân có thể kiểm tra và gỡ lỗi.
Chi tiết kỹ thuật
Kiến trúc & huấn luyện: xAI cho biết grok-code-fast-1 được xây dựng từ đầu với một kiến trúc mới và tập tiền huấn luyện giàu nội dung lập trình; sau đó mô hình được tinh chỉnh hậu huấn luyện trên các dữ liệu pull request/mã nguồn chất lượng cao, thực tế. Quy trình kỹ thuật này nhằm khiến mô hình trở nên thực dụng trong các quy trình mang tính tác nhân (IDE + sử dụng công cụ).
Triển khai & ngữ cảnh: grok-code-fast-1 và các kiểu sử dụng điển hình giả định đầu ra dạng streaming, gọi hàm và bơm ngữ cảnh phong phú (tải lên/bộ sưu tập tệp). Nhiều marketplace đám mây và adapter nền tảng đã niêm yết mô hình với hỗ trợ ngữ cảnh lớn ( 256k ngữ cảnh ở một số adapter).
Tính năng khả dụng: dấu vết lập luận hiển thị (mô hình thể hiện kế hoạch/sử dụng công cụ), hướng dẫn prompt-engineering và ví dụ tích hợp, cùng các tích hợp đối tác ra mắt sớm (ví dụ: GitHub Copilot, Cursor).
Hiệu năng benchmark (điểm số đạt được)
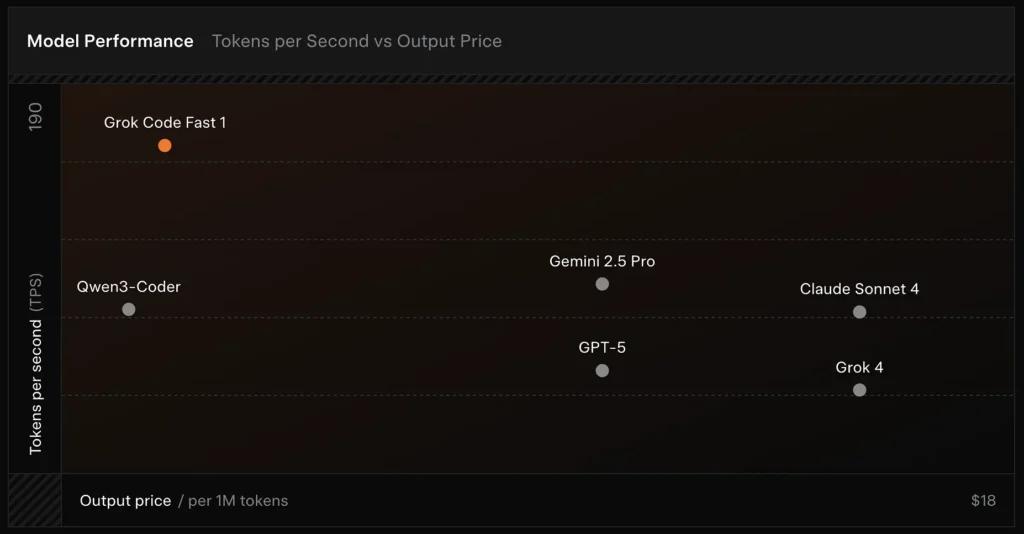
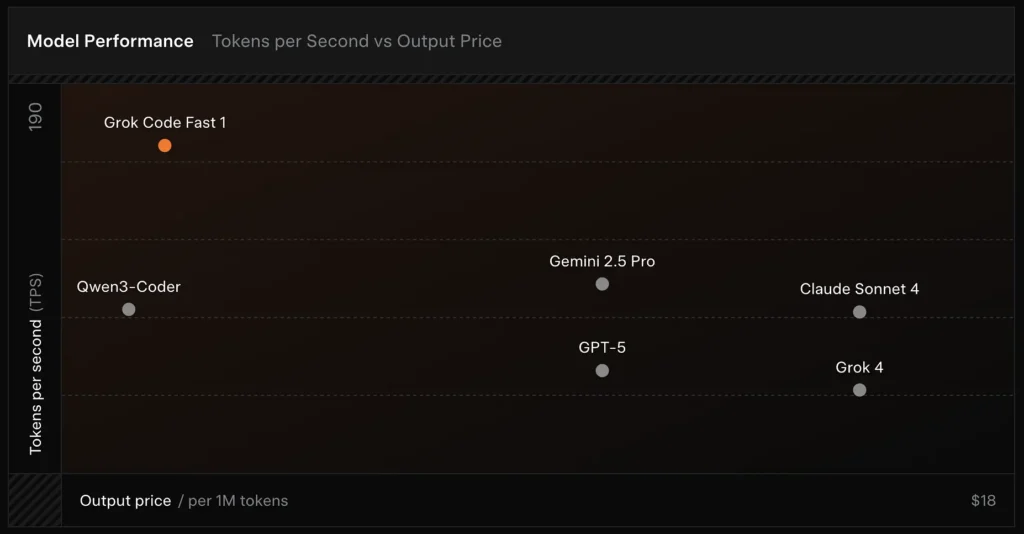
SWE-Bench-Verified: xAI báo cáo điểm 70.8% trên bộ đo nội bộ của họ đối với tập con SWE-Bench-Verified — một benchmark thường được dùng để so sánh các mô hình kỹ nghệ phần mềm. Một đánh giá thực nghiệm gần đây ghi nhận điểm đánh giá trung bình của con người ≈ 7.6 trên một bộ bài kiểm tra mã hóa hỗn hợp — cạnh tranh với một số mô hình giá trị cao (ví dụ: Gemini 2.5 Pro) nhưng kém hơn các mô hình đa phương thức/“best-reasoner” như Claude Opus 4 và Grok 4 của xAI ở các tác vụ lập luận độ khó cao. Các benchmark cũng cho thấy sai khác theo tác vụ: xuất sắc cho các sửa lỗi phổ biến và sinh mã súc tích, yếu hơn ở một số bài toán ngách hoặc đặc thù thư viện (ví dụ Tailwind CSS).
Comparison :
- vs Grok 4: Grok-code-fast-1 đánh đổi một phần độ chính xác tuyệt đối và lập luận sâu hơn để có chi phí thấp hơn nhiều và thông lượng nhanh hơn; Grok 4 vẫn là lựa chọn có năng lực cao hơn.
- vs Claude Opus / GPT-class: Các mô hình đó thường dẫn đầu ở các tác vụ phức tạp, sáng tạo hoặc đòi hỏi lập luận khó; Grok-code-fast-1 cạnh tranh tốt ở các tác vụ khối lượng lớn, thường nhật của nhà phát triển, nơi độ trễ và chi phí quan trọng.
Hạn chế & rủi ro
Các hạn chế thực tế đã quan sát đến nay:
- Khoảng trống miền: hiệu năng giảm trên các thư viện ngách hoặc bài toán được đặt vấn đề khác thường (ví dụ gồm các trường hợp rìa của Tailwind CSS).
- Đánh đổi chi phí token lập luận: vì mô hình có thể phát ra token lập luận nội bộ, lập luận mang tính tác nhân/chi tiết có thể làm tăng độ dài (và chi phí) của đầu ra suy luận.
- Độ chính xác / trường hợp rìa: dù mạnh ở các tác vụ thường nhật, Grok-code-fast-1 có thể hallucinate hoặc tạo mã sai cho thuật toán mới hoặc đề bài mang tính đối kháng; có thể kém hơn các mô hình tập trung lập luận hàng đầu trên các benchmark thuật toán khắt khe.
Trường hợp sử dụng điển hình
- Hỗ trợ IDE & tạo mẫu nhanh: hoàn thành nhanh, ghi mã tăng dần, và gỡ lỗi tương tác.
- Tác nhân tự động / quy trình mã: các tác nhân điều phối kiểm thử, chạy lệnh và chỉnh sửa tệp (ví dụ: trợ lý CI, bot reviewer).
- Nhiệm vụ kỹ thuật hằng ngày: tạo khung mã, tái cấu trúc, gợi ý phân loại lỗi, và dàn khung dự án đa tệp, nơi độ trễ thấp cải thiện đáng kể dòng chảy làm việc của nhà phát triển.
Cách gọi API grok-code-fast-1 từ CometAPI
Giá API grok-code-fast-1 trong CometAPI,giảm 20% so với giá chính thức:
- Input Tokens: $0.16/ M tokens
- Output Tokens: $2.0/ M tokens
Các bước bắt buộc
- Đăng nhập vào cometapi.com. Nếu bạn chưa là người dùng của chúng tôi, vui lòng đăng ký trước
- Lấy khóa API truy cập của giao diện. Nhấp “Add Token” tại mục API token trong trung tâm cá nhân, nhận khóa token: sk-xxxxx và gửi.
Phương thức sử dụng
- Chọn endpoint “
grok-code-fast-1” để gửi yêu cầu API và thiết lập phần thân yêu cầu. Phương thức và phần thân yêu cầu được lấy từ tài liệu API trên trang web của chúng tôi. Trang web cũng cung cấp bài kiểm thử Apifox để bạn tiện thử nghiệm. - Thay thế <YOUR_API_KEY> bằng khóa CometAPI thực tế trong tài khoản của bạn.
- Chèn câu hỏi hoặc yêu cầu của bạn vào trường content — đây là nội dung mô hình sẽ phản hồi.
- . Xử lý phản hồi API để lấy câu trả lời được tạo.
CometAPI cung cấp REST API tương thích hoàn toàn — để di chuyển trơn tru. Thông tin chính tại API doc:
- Base URL: https://api.cometapi.com/v1/chat/completions
- Model Names: “
grok-code-fast-1“ - Authentication: Bearer token qua
Authorization: Bearer YOUR_CometAPI_API_KEYheader - Content-Type:
application/json.
Tích hợp API & Ví dụ
Đoạn Python cho lời gọi ChatCompletion qua CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-code-fast-1's main features."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Xem thêm Grok 4