Especificaciones técnicas de GLM-5.2
| Elemento | GLM-5.2 |
|---|---|
| Proveedor | Zhipu AI |
| Fecha de lanzamiento | June 13, 2026 |
| Tipo de modelo | LLM Mixture-of-Experts (MoE) de pesos abiertos |
| Parámetros totales | ~744B |
| Parámetros activos | ~40B por token |
| Ventana de contexto | 1,000,000 tokens |
| Salida máxima | 131,072 tokens |
| Modos de razonamiento | Alta, Máxima |
| Licencia | MIT |
| Enfoque principal | Codificación orientada a agentes, ingeniería de software, razonamiento a largo plazo |
| Disponibilidad de la API | Plataforma Z.ai y proveedores compatibles |
| Pesos abiertos | Sí |
GLM-5.2 es el último modelo insignia de la familia GLM de Zhipu AI. A diferencia de los modelos de frontera de propósito general, GLM-5.2 se posiciona principalmente como un modelo orientado primero al código y a agentes, diseñado para ingeniería de software a escala de repositorio, flujos de trabajo autónomos y razonamiento de contexto extremadamente largo. Su capacidad principal es una ventana de contexto nativa de 1 millón de tokens, lo que la convierte en una de las ventanas de contexto más grandes disponibles públicamente entre los modelos de pesos abiertos.
Características principales de GLM-5.2
- Ventana de contexto de 1M tokens para repositorios completos, conjuntos de documentación extensos y flujos de trabajo de agentes de múltiples sesiones.
- Optimización con prioridad en el código, enfocada en refactorización, depuración, generación de código y tareas de ingeniería de software.
- Compatibilidad con flujos de trabajo orientados a agentes para herramientas como Claude Code, Cline, Roo Code, OpenCode y agentes de codificación similares.
- Lanzamiento con pesos abiertos bajo licencia MIT, lo que permite el autoalojamiento y el fine-tuning.
- Dos modos de razonamiento (Alta y Máxima) que permiten equilibrar la latencia y la profundidad de razonamiento.
- Arquitectura MoE grande con aproximadamente 744B de parámetros totales, activando solo ~40B por token para mayor eficiencia.
Rendimiento en benchmarks de GLM-5.2
Zhipu no publicó resultados oficiales completos de benchmarks en el lanzamiento, lo que hace que el benchmarking directo sea más incierto que para modelos como GPT-5 o Claude. Varios informes de la industria señalan la ausencia de publicaciones de benchmarks validadas de forma independiente.
| Benchmark | Puntuación reportada |
|---|---|
| Terminal-Bench 2.1 | 81.0 |
| SWE-Bench Pro | 62.1 |
| NL2Repo | 48.9 |
| AIME 2026 | 99.2 |
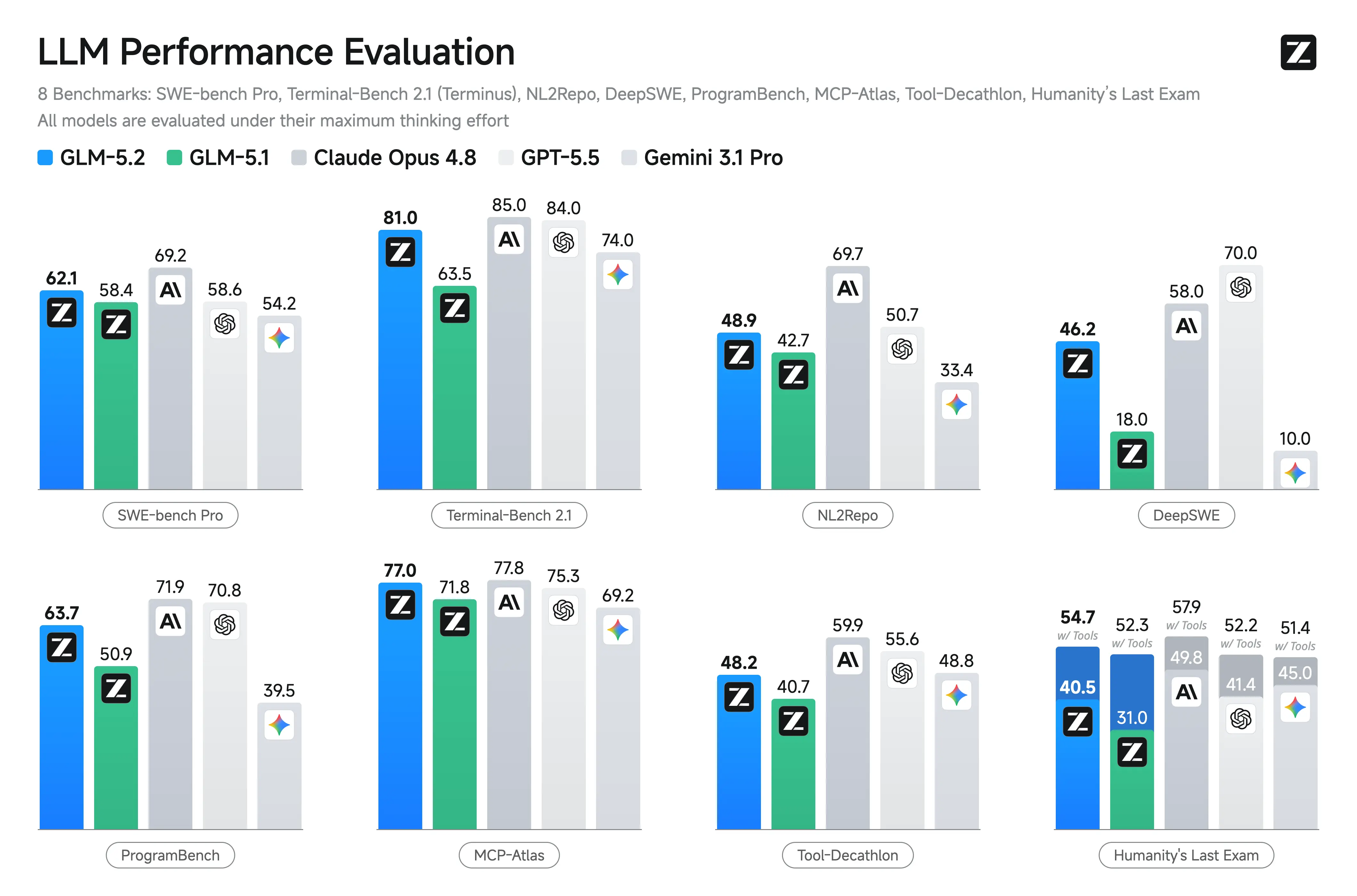
GLM-5.2 vs GLM-5.1 vs Claude Opus 4.8
| Especificación | GLM-5.2 | GLM-5.1 | Claude Opus 4.8 |
|---|---|---|---|
| Fecha de lanzamiento | 2026-06-13 | 2026 | 2026 |
| Ventana de contexto | 1,000,000 | ~200,000 | 1,000,000 |
| Pesos abiertos | Sí (MIT) | Sí | No |
| Modos de razonamiento | Alta, Máxima | Estándar | Pensamiento extendido |
| Parámetros totales | 744B | 744B | No divulgado |
| Parámetros activos | 40B | 40B | No divulgado |
| Datos oficiales de benchmark | No publicados | Publicados en el lanzamiento | Publicados |
La principal mejora documentada de GLM-5.2 sobre GLM-5.1 es su expansión a una ventana de contexto de 1M tokens y la introducción de modos de razonamiento seleccionables Alta y Máxima. En el lanzamiento, Z.ai no publicó resultados oficiales de SWE-Bench, LiveCodeBench, HumanEval u otros benchmarks similares, por lo que las comparaciones de rendimiento frente a Claude Opus 4.8, GPT-5, DeepSeek o modelos Qwen siguen sin verificarse.
Comparado con otros modelos abiertos, el principal diferenciador de GLM-5.2 es su combinación de una ventana de contexto muy grande, especialización en codificación y licencia MIT. Su mayor atractivo es para la ingeniería de software a escala de repositorio más que para aplicaciones de chat generales.
¿Por qué usar GLM-5.2 a través de CometAPI?
CometAPI permite a los desarrolladores integrar GLM-5.2 usando la misma interfaz empleada para decenas de modelos de IA líderes.
Los beneficios incluyen:
- Autenticación unificada en múltiples proveedores
- Integración de API compatible con OpenAI
- Facturación y gestión de uso simplificadas
- Experimentación rápida con modelos alternativos
- Cambio sencillo entre modelos de código, razonamiento, imagen, audio y video
- Menor dependencia de proveedores en sistemas de producción
Ya sea que esté creando un IDE de IA, un asistente interno de ingeniería o una plataforma de automatización empresarial, CometAPI minimiza el esfuerzo de integración a la vez que preserva la flexibilidad.
Cómo acceder a la API de GLM-5.2 en CometAPI
Comience con nuestro producto en unos pocos pasos sencillos...
Paso 1: Regístrese para obtener su clave de API de GLM-5.2
Cree una cuenta en Kie.ai y navegue al panel de la API para generar su clave de API de GLM-5.2. Esta clave autentica todas sus solicitudes y le da acceso inmediato a todas las capacidades de la API de GLM-5.2, incluida la ventana de contexto de 1M tokens y 128k tokens de salida.
Paso 2: Envíe solicitudes a la API de GLM-5.2
Use su clave de API de GLM-5.2 para enviar solicitudes POST al endpoint de Kie.ai. Pase su prompt, configure parámetros del modelo como el nivel de esfuerzo y el máximo de tokens, y la API de GLM-5.2 procesará su solicitud — gestionando desde la generación de código hasta el análisis de documentos y el uso de herramientas orientadas a agentes.
Paso 3: Recupere resultados e integre la API de GLM-5.2
La API de GLM-5.2 entrega respuestas estructuradas, incluyendo el texto de finalización, instrucciones de llamada a herramientas y metadatos de uso de tokens. Admite tanto respuestas síncronas estándar como transmisión en tiempo real mediante Server-Sent Events (SSE) cuando stream: true está configurado. El endpoint puede integrarse fácilmente en sus flujos de trabajo existentes utilizando clientes HTTP estándar o SDKs compatibles con OpenAI, enrutando las solicitudes a través de url(//api.cometapi.com/v1) con su Bearer Token.