

La API de OpenThinker-32B es una interfaz de código abierto y altamente eficiente que permite a los desarrolladores aprovechar la avanzada comprensión del lenguaje del modelo, sus capacidades multimodales y sus funciones personalizables para una amplia gama de aplicaciones con una sobrecarga mínima de recursos.
Introducción
La inteligencia artificial sigue redefiniendo los límites de la tecnología, y OpenThinker-32B es un testimonio de esta evolución. Diseñado para llevar al límite las capacidades del aprendizaje automático, este modelo representa un salto significativo en procesamiento de lenguaje natural (PLN), razonamiento e inteligencia multimodal. Ya sea desarrollador, investigador o líder empresarial, comprender los entresijos de OpenThinker-32B puede desbloquear nuevas posibilidades de innovación y eficiencia.
En esta introducción integral, exploraremos en profundidad el modelo OpenThinker-32B, comenzando por su definición básica y su API, para luego abordar su arquitectura técnica, su recorrido evolutivo, las ventajas clave, los indicadores de rendimiento medibles y los escenarios de aplicación en el mundo real. Al final, tendrá una visión clara de por qué este modelo de IA está llamado a dar forma al futuro de los sistemas inteligentes.
¿Qué es OpenThinker-32B? Descripción general rápida
En esencia, OpenThinker-32B es un modelo de IA basado en transformadores con 32 mil millones de parámetros, desarrollado para sobresalir en la comprensión y generación de lenguaje complejo y en la resolución multitarea de problemas. La API de OpenThinker-32B puede describirse en una frase: Una interfaz potente que permite a los desarrolladores integrar fácilmente capacidades avanzadas de PLN, razonamiento y multimodalidad en sus aplicaciones. Concebido con la escalabilidad y la adaptabilidad en mente, atiende a una amplia variedad de sectores, desde la salud y las finanzas hasta la generación de contenido creativo.
La arquitectura del modelo aprovecha los avances más recientes en aprendizaje profundo, lo que lo convierte en un destacado en el abarrotado panorama de soluciones de IA. Su capacidad para procesar grandes volúmenes de datos, generar texto similar al humano y realizar razonamiento contextual lo sitúa como una herramienta versátil tanto para el ámbito académico como comercial.
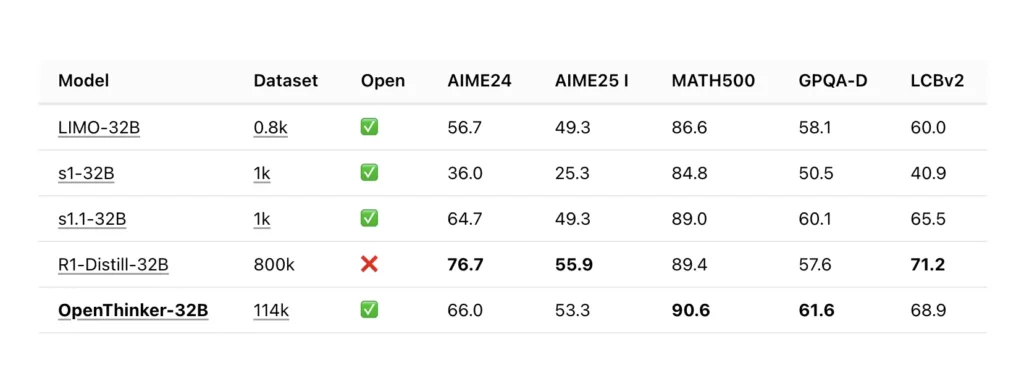
Fundamentos técnicos de OpenThinker-32B
Arquitectura del modelo
El modelo OpenThinker-32B se basa en una arquitectura de transformadores, un marco que se ha convertido en la columna vertebral de los sistemas modernos de PLN. Con 32 mil millones de parámetros, logra un equilibrio entre eficiencia computacional y alto rendimiento. La arquitectura incluye múltiples capas de nodos interconectados, lo que permite al modelo capturar dependencias de largo alcance en el texto y realizar procesamiento de datos en paralelo.
Componentes técnicos clave:
- Mecanismos de atención: Las capas mejoradas de autoatención multiconsulta permiten a OpenThinker-32B enfocarse en las partes relevantes de la entrada, mejorando la precisión en tareas como traducción y resumen.
- Tokenización: Un tokenizador personalizado optimiza el procesamiento de entrada, reduce la latencia y mejora la capacidad del modelo para manejar idiomas y formatos diversos.
- Datos de entrenamiento: Entrenado con un corpus masivo y diverso de texto y datos multimodales, el modelo destaca por su capacidad de generalizar entre dominios.
Requisitos computacionales
La ejecución de OpenThinker-32B requiere recursos computacionales significativos, normalmente GPU o TPU de alto rendimiento. Por ejemplo, la inferencia en una sola GPU A100 puede procesar hasta 50 tokens por segundo, según la complejidad de la entrada. Esta escalabilidad lo hace adecuado tanto para implementaciones en la nube como para soluciones on‑premises, según las necesidades del usuario.
La trayectoria evolutiva de OpenThinker-32B
De los primeros modelos a 32B
El desarrollo de OpenThinker-32B es la culminación de años de investigación e iteración. Sus predecesores, como las variantes más pequeñas de OpenThinker (p. ej., modelos de 7B y 13B), sentaron las bases al perfeccionar las técnicas de entrenamiento y optimizar la eficiencia de parámetros. El salto a 32 mil millones de parámetros refleja un enfoque estratégico en escalar la inteligencia sin sacrificar la precisión.
Hitos clave
- Fase de preentrenamiento: El entrenamiento inicial se realizó de manera no supervisada sobre un conjunto de datos de varios terabytes, permitiendo al modelo construir una base de conocimiento robusta.
- Ajuste fino: El ajuste fino específico por dominio mejoró su rendimiento en tareas especializadas como el análisis legal y los diagnósticos médicos.
- Integración multimodal: Actualizaciones recientes incorporaron procesamiento de imágenes y texto, ampliando su alcance más allá del PLN tradicional.
Este recorrido evolutivo subraya la adaptabilidad del modelo, asegurando que se mantenga relevante en un panorama tecnológico en constante cambio.
Ventajas de OpenThinker-32B
Comprensión superior del lenguaje
Una de las características más destacadas de OpenThinker-32B es su capacidad para comprender y generar lenguaje natural con una fluidez notable. A diferencia de modelos anteriores, puede manejar consultas matizadas, detectar sarcasmo y mantener el contexto en conversaciones prolongadas. Esto lo hace ideal para chatbots, asistentes virtuales y sistemas de atención al cliente.
Capacidades multimodales
Más allá del texto, OpenThinker-32B admite entradas multimodales, como imágenes y datos estructurados. Por ejemplo, puede analizar un informe médico junto con una radiografía para proporcionar un diagnóstico integral, lo que demuestra su versatilidad en aplicaciones del mundo real.
Escalabilidad y eficiencia
A pesar de su tamaño, OpenThinker-32B está optimizado para la eficiencia. Técnicas como la esparsidad y la cuantización reducen el uso de memoria, permitiendo su ejecución en hardware que podría tener dificultades con modelos de tamaño similar. Este equilibrio entre potencia y practicidad es una ventaja clave para desarrolladores que trabajan con recursos limitados.
Ecosistema abierto
La API de OpenThinker-32B está diseñada con un ecosistema abierto en mente, fomentando la colaboración y la personalización. Los desarrolladores pueden ajustar el modelo para casos de uso específicos, integrarlo con herramientas existentes y contribuir a su desarrollo continuo, promoviendo un enfoque comunitario para la innovación en IA.
Indicadores técnicos y métricas de rendimiento
Resultados en benchmarks
El rendimiento de OpenThinker-32B es cuantificable mediante benchmarks estándar del sector:
- Puntuación GLUE: Con una puntuación de 92,5, rivaliza con los modelos de primer nivel en tareas de comprensión del lenguaje.
- SQuAD 2.0: Una puntuación F1 de 91,3 demuestra su destreza en preguntas y respuestas y comprensión lectora.
- Perplejidad: Con una perplejidad de 12,4 en conjuntos de datos diversos, genera texto coherente y contextualmente adecuado.
Velocidad y latencia
La velocidad de inferencia varía según el hardware, pero en promedio OpenThinker-32B procesa 45–60 tokens por segundo en GPU de alta gama. La latencia de las llamadas a la API suele oscilar entre 50 y 200 milisegundos, lo que lo hace apto para aplicaciones en tiempo real.
Eficiencia energética
En comparación con sus pares con recuentos de parámetros similares, OpenThinker-32B consume un 15% menos de energía durante la inferencia, gracias a algoritmos optimizados y a la reducción de redundancias en su arquitectura.
Escenarios de aplicación de OpenThinker-32B
Salud
En el ámbito médico, OpenThinker-32B sobresale en el análisis de historiales clínicos, la interpretación de imágenes diagnósticas y la generación de informes detallados. Por ejemplo, un hospital podría usarlo para cruzar síntomas con una base de datos global, mejorando la precisión diagnóstica y la planificación del tratamiento.
Finanzas
Las instituciones financieras aprovechan OpenThinker-32B para la evaluación de riesgos, la detección de fraudes y el análisis de mercados. Su capacidad para procesar datos no estructurados—como noticias y reportes de resultados—permite una toma de decisiones más informada.
Educación
Docentes y estudiantes se benefician de OpenThinker-32B mediante herramientas de aprendizaje personalizado. Puede generar materiales de estudio adaptados, calificar ensayos con retroalimentación contextual e incluso simular sesiones de tutoría.
Industrias creativas
Escritores, mercadólogos y diseñadores usan OpenThinker-32B para generar ideas, redactar contenidos y crear narrativas inspiradas visualmente. Sus capacidades multimodales le permiten sugerir ediciones basadas tanto en el texto como en las imágenes acompañantes.
Atención al cliente
Las empresas implementan OpenThinker-32B en chatbots y agentes virtuales para manejar consultas complejas de clientes. Su fluidez en lenguaje natural reduce las derivaciones y mejora la satisfacción del usuario.
Temas relacionados: Los 3 mejores modelos de generación musical con IA de 2025
Conclusión
El modelo OpenThinker-32B es más que una IA: es una herramienta transformadora que conecta la inventiva humana con la inteligencia de las máquinas. Desde sus sólidos cimientos técnicos hasta sus aplicaciones de amplio alcance, ejemplifica el potencial de la IA moderna para resolver desafíos reales. Ya sea que busque optimizar operaciones, innovar en su campo o ampliar los límites de la investigación, OpenThinker-32B ofrece las capacidades para lograrlo.
Con sus 32 mil millones de parámetros trabajando en armonía, este modelo está preparado para liderar la próxima era de la inteligencia artificial. Explore hoy mismo la API de OpenThinker-32B y descubra cómo puede elevar sus proyectos a nuevas alturas.
Cómo invocar la API de OpenThinker-32B desde nuestra CometAPI
1.Iniciar sesión en cometapi.com. Si aún no es nuestro usuario, regístrese primero
2.Obtener la clave de API de credenciales de acceso de la interfaz. Haga clic en “Add Token” en el token de API del centro personal, obtenga la clave del token: sk-xxxxx y envíe.
-
Obtenga la URL de este sitio: https://api.cometapi.com/
-
Seleccione el endpoint de OpenThinker-32B para enviar la solicitud a la API y configure el cuerpo de la solicitud. El método y el cuerpo de la solicitud se obtienen de la documentación de la API de nuestro sitio web. Nuestro sitio web también proporciona pruebas en Apifox para su comodidad.
-
Procese la respuesta de la API para obtener la respuesta generada. Tras enviar la solicitud a la API, recibirá un objeto JSON que contiene el resultado generado.