

Interfejs API OpenThinker-32B to otwartoźródłowe, wysoce wydajne rozwiązanie, które umożliwia deweloperom wykorzystanie zaawansowanego rozumienia języka, możliwości wielomodalnych oraz funkcji dostosowywania modelu w szerokim zakresie zastosowań przy minimalnym narzucie zasobów.
Wprowadzenie
Sztuczna inteligencja nieustannie redefiniuje granice technologii, a OpenThinker-32B stanowi świadectwo tej ewolucji. Zaprojektowany, by przesuwać granice możliwości uczenia maszynowego, model ten reprezentuje znaczący krok naprzód w zakresie przetwarzania języka naturalnego (NLP), rozumowania oraz inteligencji wielomodalnej. Niezależnie od tego, czy jesteś deweloperem, badaczem, czy liderem biznesu, zrozumienie niuansów OpenThinker-32B może otworzyć nowe możliwości innowacji i efektywności.
W tym kompleksowym wprowadzeniu przyjrzymy się szczegółowo modelowi OpenThinker-32B, zaczynając od jego podstawowej definicji i API, przez architekturę techniczną, historię rozwoju, kluczowe zalety, mierzalne wskaźniki wydajności po scenariusze zastosowań w realnym świecie. Na końcu zyskasz jasny obraz tego, dlaczego ten model SI jest gotów kształtować przyszłość inteligentnych systemów.
Czym jest OpenThinker-32B? Krótki przegląd
W swojej istocie OpenThinker-32B to oparty na transformerach model SI z 32 miliardami parametrów, opracowany, by doskonale radzić sobie złożonym rozumieniem języka, generowaniem treści oraz rozwiązywaniem problemów wielozadaniowych. OpenThinker-32B API można opisać jednym zdaniem: Potężny interfejs, który pozwala deweloperom z łatwością integrować zaawansowane możliwości NLP, rozumowania i wielomodalności z aplikacjami. Zaprojektowany z myślą o skalowalności i elastyczności, odpowiada potrzebom szerokiej gamy branż — od ochrony zdrowia, przez finanse, po kreatywne generowanie treści.
Architektura modelu wykorzystuje najnowsze osiągnięcia głębokiego uczenia, dzięki czemu wyróżnia się na tle licznych rozwiązań AI. Zdolność do przetwarzania ogromnych zbiorów danych, generowania tekstu zbliżonego do ludzkiego oraz kontekstowego rozumowania czyni go wszechstronnym narzędziem zarówno dla środowisk akademickich, jak i komercyjnych.
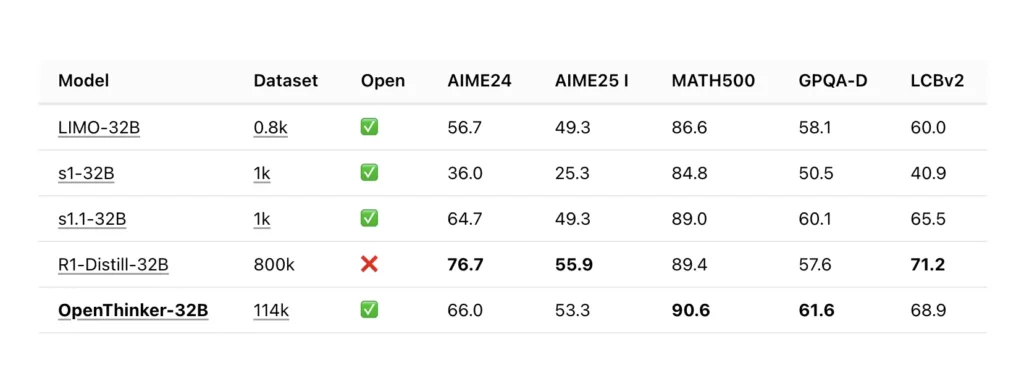
Techniczne podstawy OpenThinker-32B
Architektura modelu
Model OpenThinker-32B zbudowano w oparciu o architekturę transformer, która stała się fundamentem nowoczesnych systemów NLP. Dzięki 32 miliardom parametrów łączy on efektywność obliczeniową z wysoką wydajnością. Architektura obejmuje wiele warstw połączonych węzłów, co umożliwia uchwycenie długodystansowych zależności w tekście i równoległe przetwarzanie danych.
Kluczowe komponenty techniczne obejmują:
- Mechanizmy uwagi: Udoskonalone wielogłowe warstwy self-attention pozwalają OpenThinker-32B koncentrować się na istotnych częściach danych wejściowych, poprawiając dokładność w zadaniach takich jak tłumaczenie i streszczanie.
- Tokenizacja: Niestandardowy tokenizer optymalizuje przetwarzanie wejścia, redukując opóźnienia i zwiększając zdolność modelu do obsługi różnorodnych języków i formatów.
- Dane treningowe: Trenowany na ogromnym, zróżnicowanym korpusie tekstu i danych wielomodalnych, model doskonale się uogólnia w różnych domenach.
Wymagania obliczeniowe
Uruchamianie OpenThinker-32B wymaga znaczących zasobów obliczeniowych, zwykle z wykorzystaniem wysokowydajnych kart GPU lub TPU. Na przykład inferencja na pojedynczym GPU A100 może przetwarzać do 50 tokenów na sekundę, w zależności od złożoności wejścia. Ta skalowalność sprawia, że model nadaje się zarówno do wdrożeń w chmurze, jak i rozwiązań on-premises, zależnie od potrzeb użytkownika.
Ewolucja OpenThinker-32B
Od wczesnych modeli do 32B
Rozwój OpenThinker-32B to zwieńczenie lat badań i iteracji. Jego poprzednicy, tacy jak mniejsze warianty OpenThinker (np. modele 7B i 13B), utorowali drogę, udoskonalając techniki treningowe i optymalizując efektywność parametrów. Skok do 32 miliardów parametrów odzwierciedla strategiczne skupienie na skalowaniu inteligencji bez poświęcania precyzji.
Kluczowe kamienie milowe
- Faza pretrenowania: Początkowe szkolenie obejmowało uczenie niesuperwizyjne na wieloterabajtowym zbiorze danych, co pozwoliło modelowi zbudować solidną bazę wiedzy.
- Dostrajanie: Dostrajanie ukierunkowane na konkretne domeny zwiększyło wydajność w wyspecjalizowanych zadaniach, takich jak analizy prawne czy diagnostyka medyczna.
- Integracja wielomodalna: Ostatnie aktualizacje włączyły przetwarzanie obrazu i tekstu, poszerzając zakres możliwości poza tradycyjne NLP.
Ta ścieżka rozwoju podkreśla zdolność modelu do adaptacji, zapewniając jego aktualność w nieustannie zmieniającym się krajobrazie technologicznym.
Zalety OpenThinker-32B
Ponadprzeciętne rozumienie języka
Jedną z wyróżniających cech OpenThinker-32B jest zdolność do rozumienia i generowania języka naturalnego z niezwykłą płynnością. W odróżnieniu od wcześniejszych modeli potrafi obsługiwać zniuansowane zapytania, wykrywać sarkazm i utrzymywać kontekst podczas długich rozmów. Czyni to go idealnym rozwiązaniem dla chatbotów, wirtualnych asystentów i systemów obsługi klienta.
Możliwości wielomodalne
Poza tekstem OpenThinker-32B obsługuje wejścia wielomodalne, takie jak obrazy i dane ustrukturyzowane. Na przykład potrafi przeanalizować raport medyczny wraz ze zdjęciem RTG, aby dostarczyć kompleksową diagnozę, co pokazuje jego wszechstronność w realnych zastosowaniach.
Skalowalność i efektywność
Mimo swoich rozmiarów OpenThinker-32B jest zoptymalizowany pod kątem efektywności. Techniki takie jak sparsity i kwantyzacja zmniejszają zużycie pamięci, pozwalając uruchamiać go na sprzęcie, który mógłby mieć problemy z modelami o podobnej wielkości. To połączenie mocy i praktyczności jest kluczową zaletą dla deweloperów pracujących z ograniczonymi zasobami.
Otwarty ekosystem
OpenThinker-32B API zaprojektowano z myślą o otwartym ekosystemie, zachęcając do współpracy i personalizacji. Deweloperzy mogą dostrajać model do konkretnych przypadków użycia, integrować go z istniejącymi narzędziami i wnosić wkład w jego dalszy rozwój, wspierając społecznościowe podejście do innowacji w AI.
Wskaźniki techniczne i metryki wydajności
Wyniki benchmarków
Wydajność OpenThinker-32B jest mierzalna za pomocą branżowych benchmarków:
- Wynik GLUE: Osiągając 92.5, rywalizuje z modelami najwyższej klasy w zadaniach rozumienia języka.
- SQuAD 2.0: Wynik F1 na poziomie 91.3 potwierdza jego możliwości w odpowiadaniu na pytania i rozumieniu czytanego tekstu.
- Perpleksja: Przy wartości 12.4 na zróżnicowanych zbiorach danych generuje spójny i kontekstowo adekwatny tekst.
Szybkość i opóźnienia
Prędkość inferencji zależy od sprzętu, ale średnio OpenThinker-32B przetwarza 45-60 tokenów na sekundę na wydajnych GPU. Opóźnienie wywołań API zwykle mieści się w zakresie 50-200 milisekund, co czyni go odpowiednim do zastosowań w czasie rzeczywistym.
Efektywność energetyczna
W porównaniu z modelami o podobnej liczbie parametrów OpenThinker-32B zużywa o 15% mniej energii podczas inferencji, dzięki zoptymalizowanym algorytmom i zredukowanej redundancji w architekturze.
Scenariusze zastosowań OpenThinker-32B
Ochrona zdrowia
W medycynie OpenThinker-32B wyróżnia się analizą dokumentacji pacjentów, interpretacją obrazów diagnostycznych i generowaniem szczegółowych raportów. Na przykład szpital może użyć go do zestawiania objawów z globalną bazą danych, poprawiając trafność diagnoz i planowanie terapii.
Finanse
Instytucje finansowe wykorzystują OpenThinker-32B do oceny ryzyka, wykrywania nadużyć i analizy rynku. Zdolność do przetwarzania danych nieustrukturyzowanych — takich jak artykuły prasowe i raporty wynikowe — umożliwia podejmowanie lepiej uzasadnionych decyzji.
Edukacja
Nauczyciele i studenci korzystają z OpenThinker-32B dzięki spersonalizowanym narzędziom edukacyjnym. Może generować dopasowane materiały do nauki, oceniać wypracowania z kontekstową informacją zwrotną, a nawet symulować sesje tutoringu.
Branże kreatywne
Pisarze, marketerzy i projektanci używają OpenThinker-32B do burzy mózgów, tworzenia treści i budowania narracji inspirowanych wizualnie. Jego możliwości wielomodalne pozwalają sugerować poprawki zarówno na podstawie tekstu, jak i dołączonych obrazów.
Obsługa klienta
Firmy wdrażają OpenThinker-32B w chatbotach i wirtualnych agentach do obsługi złożonych zapytań klientów. Naturalna płynność językowa obniża odsetek eskalacji i podnosi satysfakcję użytkowników.
Powiązane tematy:3 najlepsze modele generowania muzyki AI w 2025 r.
Podsumowanie
Model OpenThinker-32B to coś więcej niż tylko AI — to transformacyjne narzędzie łączące ludzką pomysłowość z inteligencją maszyn. Od solidnych podstaw technicznych po szerokie zastosowania, stanowi przykład potencjału nowoczesnej AI w rozwiązywaniu realnych problemów. Niezależnie od tego, czy chcesz usprawnić operacje, wprowadzić innowacje w swojej dziedzinie, czy przesunąć granice badań, OpenThinker-32B dostarcza możliwości, by to osiągnąć.
Dzięki harmonijnej pracy 32 miliardów parametrów ten model jest gotów poprowadzić rozwój sztucznej inteligencji w kolejną erę. Poznaj OpenThinker-32B API już dziś i przekonaj się, jak może wynieść Twoje projekty na nowy poziom.
Jak wywołać OpenThinker-32B API z naszego CometAPI
-
Zaloguj się na cometapi.com. Jeśli nie jesteś jeszcze naszym użytkownikiem, najpierw się zarejestruj
-
Uzyskaj klucz dostępu API do interfejsu. Kliknij „Add Token” w sekcji tokenów API w centrum osobistym, uzyskaj token: sk-xxxxx i zatwierdź.
-
Pobierz adres URL tej usługi: https://api.cometapi.com/
-
Wybierz endpoint OpenThinker-32B, aby wysłać żądanie do API i ustaw ciało żądania. Metodę i ciało żądania znajdziesz w dokumentacji API na naszej stronie. Dla wygody udostępniamy również test w Apifox.
-
Przetwórz odpowiedź API, aby uzyskać wygenerowaną odpowiedź. Po wysłaniu żądania API otrzymasz obiekt JSON zawierający wygenerowane uzupełnienie.