

Pada 3 Mac 2026, Google memperkenalkan Gemini 3.1 Flash-Lite, ahli terbaharu keluarga Gemini 3 yang direka khusus sebagai enjin berkapasiti tinggi, latensi rendah dan cekap kos untuk beban kerja pembangun serta perusahaan. Google memposisikan Flash-Lite sebagai model “terpantas dan paling cekap kos” dalam siri Gemini 3: satu varian ringan yang menyasarkan penyampaian interaksi penstriman, pemprosesan latar berskala besar, dan tugas pengeluaran berfrekuensi tinggi (contohnya, terjemahan, pengekstrakan, penjanaan UI dan pengelasan volum besar) pada harga yang jauh lebih rendah daripada rakan setaraf Pro.
Di bawah kami menghuraikan apakah itu Flash-Lite.
Apakah Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite ialah ahli keluarga Gemini 3 oleh Google yang secara sengaja mengorbankan sebahagian kedalaman penaakulan peringkat tertinggi demi kelajuan dan kecekapan kos. Ia secara natif adalah multimodal dalam salasilah Gemini (mampu menerima teks, imej dan modaliti lain sebagai input), tetapi ditala dan digunakan khusus untuk menyampaikan kadar token per saat maksimum serta caj per token yang jauh lebih rendah bagi beban kerja yang memerlukan inferens pantas dan berulang berbanding kedalaman kognitif maksimum. Model ini digambarkan sebagai terbitan daripada seni bina 3.1 Pro tetapi dioptimumkan untuk kadar hantaran, latensi dan kos.
Pertukaran reka bentuk utama
Gelaran "Lite" menandakan penekanan kejuruteraan model ini:
- Kadar hantaran mengatasi penaakulan berat: Flash-Lite sengaja mengurangkan pengiraan per token untuk menyampaikan Masa-ke-Token-Pertama (TTFT) yang lebih pantas dan kelajuan output berterusan. Ini menjadikannya ideal untuk rantaian pemprosesan di mana setiap permintaan perlu dilayan dengan cepat dan pada skala (cth., penapis keselamatan, pembantu masa nyata, penjanaan volum tinggi).
- Kecekapan kos untuk volum tinggi: Dengan menurunkan pengiraan per token, model boleh ditawarkan pada harga lebih rendah per sejuta token, yang mengurangkan kos marginal dalam aplikasi berskala besar (cth., berjuta hingga berbilion token sebulan). Harga pratonton Google menunjukkan perbezaan ketara berbanding tahap Pro.
- Kualiti ditala untuk tugas pragmatik: Menurut ringkasan pemarkahan awal, Flash-Lite mengekalkan keputusan kukuh pada standard pengelasan, berbilang bahasa dan banyak tugas multimodal, tetapi ia tidak diposisikan untuk mengatasi Pro pada penanda aras penaakulan berbilang langkah paling kompleks atau penjanaan kod di mana kedalaman penting.
Beban kerja ini memerlukan output yang boleh dipercayai dan kadar hantaran tinggi, tetapi tidak semestinya memerlukan keupayaan penaakulan berbilang langkah yang kompleks seperti model utama.
Ciri Utama Gemini 3.1 Flash-Lite
1. Latensi rendah dan masa token pertama yang pantas
Google menekankan metrik masa-ke-token jawapan pertama sebagai metrik utama untuk Flash-Lite. Syarikat melaporkan ~2.5× lebih pantas masa-ke-token pertama berbanding Gemini 2.5 Flash dan sehingga 45% lebih pantas penjanaan output — penambahbaikan yang secara langsung memberi kesan kepada persepsi responsif pengguna akhir dan kos kadar hantaran untuk sistem belakang tabir. Peningkatan ini menjadikan Flash-Lite sangat sesuai untuk ciri interaktif (cth., chatbot terbina dalam aplikasi) dan rantaian QPS tinggi di mana mikrosaat penting.
Peningkatan ini menambah baik aplikasi masa nyata seperti:
- AI perbualan
- pembantu carian dikuasakan AI
- chatbot interaktif
- perkhidmatan terjemahan langsung
Latensi yang lebih rendah meningkatkan pengalaman pengguna dengan mengurangkan masa menunggu dan membolehkan interaksi yang lebih lancar.
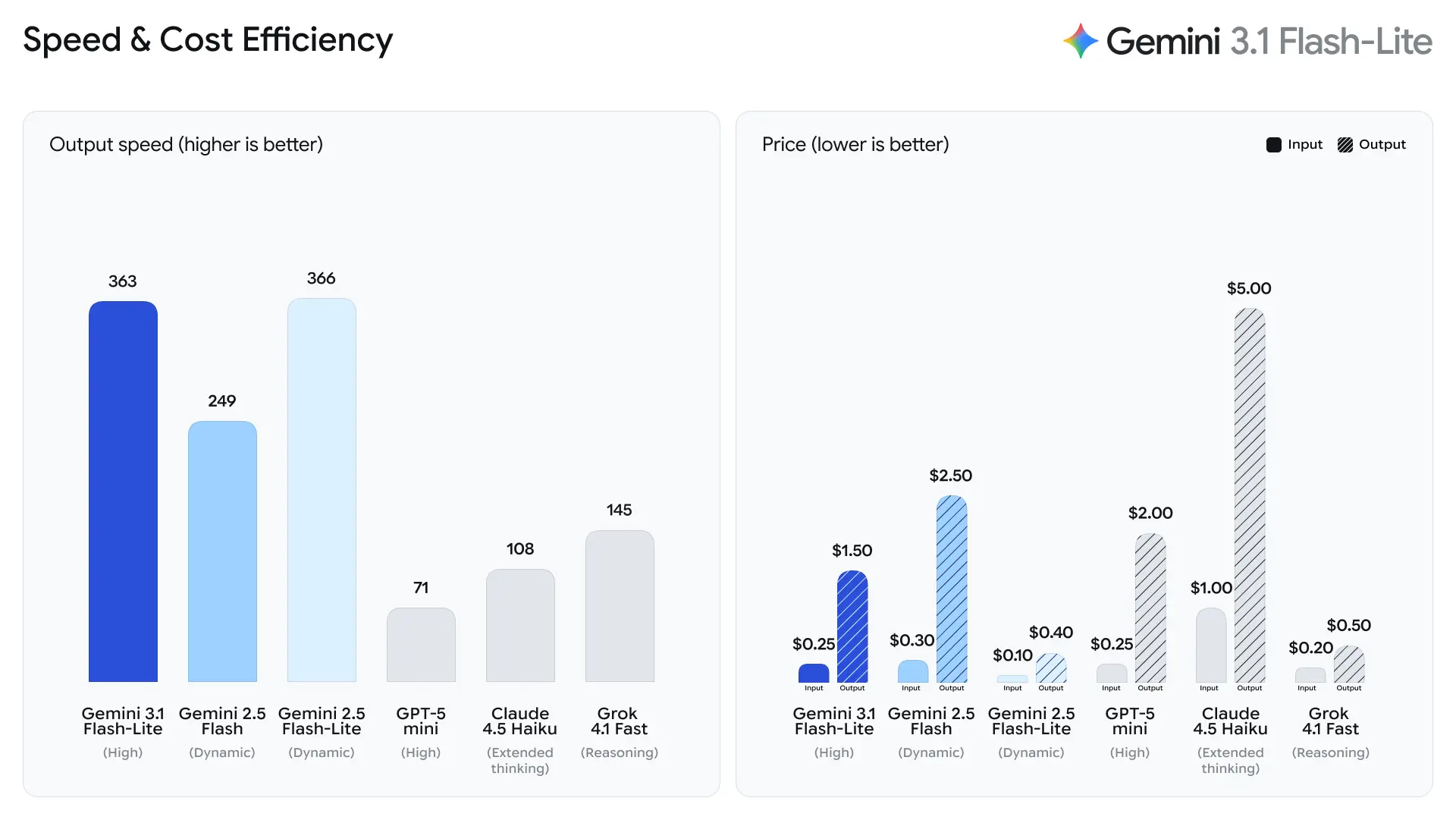
2. Harga Token Cekap Kos
Kos inferens AI selalunya dikira per token, menjadikan harga faktor kritikal untuk penyepadan berskala besar.
Gemini 3.1 Flash-Lite memperkenalkan struktur harga yang sangat kompetitif:
| Jenis Token | Harga |
|---|---|
| Token input | $0.25 per 1M token |
| Token output | $1.50 per 1M token |
Ini merupakan pengurangan berbanding model Flash sebelumnya, menjadikan model ini menarik untuk organisasi yang menjalankan beban kerja besar.
Sebagai perbandingan:
| Model | Harga Input | Harga Output |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
Strategi harga ini membolehkan pembangun menjalankan AI pada skala tanpa meningkatkan kos operasi secara mendadak.
Jika anda mencari harga yang lebih baik, maka Gemini Flash-Lite menawarkan diskaun 20% di CometAPI.
3. “Thinking levels” (kedalaman inferens boleh kawal)
Gemini 3.1 Flash-Lite menyertakan keupayaan “thinking levels” — tombol boleh dikonfigur oleh pembangun yang mengarahkan model untuk mengutamakan pemprosesan yang lebih pantas dan cetek bagi tugas remeh serta penaakulan lebih mendalam untuk tugas yang lebih sukar. Ini penting dalam amalan kerana ia membolehkan pertukaran kos/latensi dinamik per permintaan tanpa menukar model.
Pembangun boleh mengkonfigur kedalaman penaakulan model agar sepadan dengan kerumitan tugas. Thinking levels: Menyokong empat tahap: Minimum, Rendah, Sederhana dan Tinggi.
Pendekatan dinamik ini membolehkan aplikasi mengoptimumkan penggunaan sumber sambil mengekalkan kualiti pada bahagian yang penting. Secara praktikal, strateginya kira-kira seperti berikut:
- Minimum/Rendah: Sesuai untuk tugas berkeserentakan tinggi tetapi secara logik ringkas seperti terjemahan, pengelasan dan analisis sentimen, mengutamakan kelajuan maksimum dan kos minimum.
- Sederhana: Sesuai untuk kebanyakan tugas pengeluaran, mengimbangi kualiti dan kecekapan.
- Tinggi: Sesuai untuk tugas yang memerlukan penaakulan mendalam, seperti menjana antara muka pengguna, mencipta simulasi dan melaksanakan arahan kompleks.
4. Keupayaan multimodal dengan jejak ringan
Walaupun Flash-Lite dioptimumkan untuk kelajuan dan kos, ia mengekalkan asas multimodal siri Gemini 3: ia boleh menerima input imej untuk pengelasan atau penaakulan multimodal ringan apabila kes penggunaan memerlukannya — tetapi pembangun harus menjangkakan reka bentuk ekonomi lebih mengutamakan operasi multimodal yang lebih pendek dan terhad berbanding alur kerja berskala besar yang berat imej. Seperti model Gemini lain, Gemini 3.1 Flash-Lite menyokong input multimodal, membolehkan pembangun memproses pelbagai jenis data.
Input yang disokong termasuk:
- Teks
- Imej
- Video
- Audio
Keupayaan model menganalisis pelbagai jenis maklumat membolehkan kes penggunaan baharu seperti:
- pemprosesan dokumen automatik
- pengekstrakan data visual
- pemeringkasan multimedia
Model Gemini terdahulu juga menunjukkan keupayaan penaakulan multimodal yang kukuh merentasi penanda aras visual dan pengetahuan.
Penanda aras prestasi — angka sebenar dan maksudnya
Pengumuman dan dokumentasi produk Google membentangkan beberapa titik data penanda aras untuk membantu pembeli memahami kedudukan Flash-Lite dalam ekosistem.
Metrik kelajuan berorientasikan pembangun
- 2.5× lebih pantas Masa ke Token Jawapan Pertama berbanding Gemini 2.5 Flash (perbandingan dalaman yang dinyatakan Google).
- 45% lebih pantas penjanaan output berbanding Gemini 2.5 Flash.
Ini ialah metrik kejuruteraan prestasi dan bukannya metrik kualiti yang dinilai manusia; ia mencerminkan penambahbaikan dalam mikroarkitektur masa jalan, pembungkusan kelompok (batching), dan pengoptimuman timbunan inferens yang mengurangkan latensi untuk respons pendek. Masa token pertama yang lebih pantas mengurangkan ketinggalan yang dirasai dalam aplikasi interaktif dan meningkatkan kadar hantaran per pelayan secara keseluruhan, yang boleh menurunkan jumlah kos pengiraan untuk QPS yang sama.
Token per saat (t/s) dan kadar hantaran
Menurut data ujian Artificial Analysis, 3.1 Flash-Lite mencapai kelajuan output 388.8 token per saat (median untuk model dalam julat harga yang sama hanyalah 96.7 token/saat). Kelajuan ini adalah aras teratas dalam kelasnya.
Namun, Artificial Analysis juga menyorot satu masalah: latensi token pertama (TTFT) 3.1 Flash-Lite ialah 5.18 saat, yang agak tinggi untuk model inferens dalam julat harga yang sama (median ialah 1.82 saat). Selain itu, model menjana 53 juta token semasa proses penilaian, yang agak tinggi berbanding purata 20 juta. Ini bermakna jika senario anda sangat sensitif kepada latensi token pertama atau mempunyai keperluan tegas untuk kekemasan output, anda mungkin perlu mengoptimumkan tahap pemikiran dan prompt.
Skor penanda aras untuk penaakulan dan kefaktualan
Google menyertakan perbandingan rentas model yang menunjukkan Gemini 3.1 Flash-Lite berprestasi kuat menentang pesaing dan varian Gemini sebelumnya pada tugas gabungan penaakulan/kefaktualan:
- Skor Elo Arena.ai: Gemini 3.1 Flash-Lite dilaporkan mencapai Elo 1432 pada papan pendahulu penilaian Arena — kedudukan komposit secara bersemuka yang menunjukkan prestasi relatif kompetitif dalam senario perlawanan langsung.
- GPQA Diamond: 86.9% (ukuran kekukuhan soal jawab).
- MMMU Pro: 76.8% (metrik multimodal/berbilang tugas yang digunakan secara dalaman/luaran oleh sesetengah makmal).
- LiveCodeBench (Keupayaan Pengkodan): 72.0%
- CharXiv Reasoning (Penaakulan Grafik): 73.2%
- Video-MMMU (Pemahaman Video): 84.8%
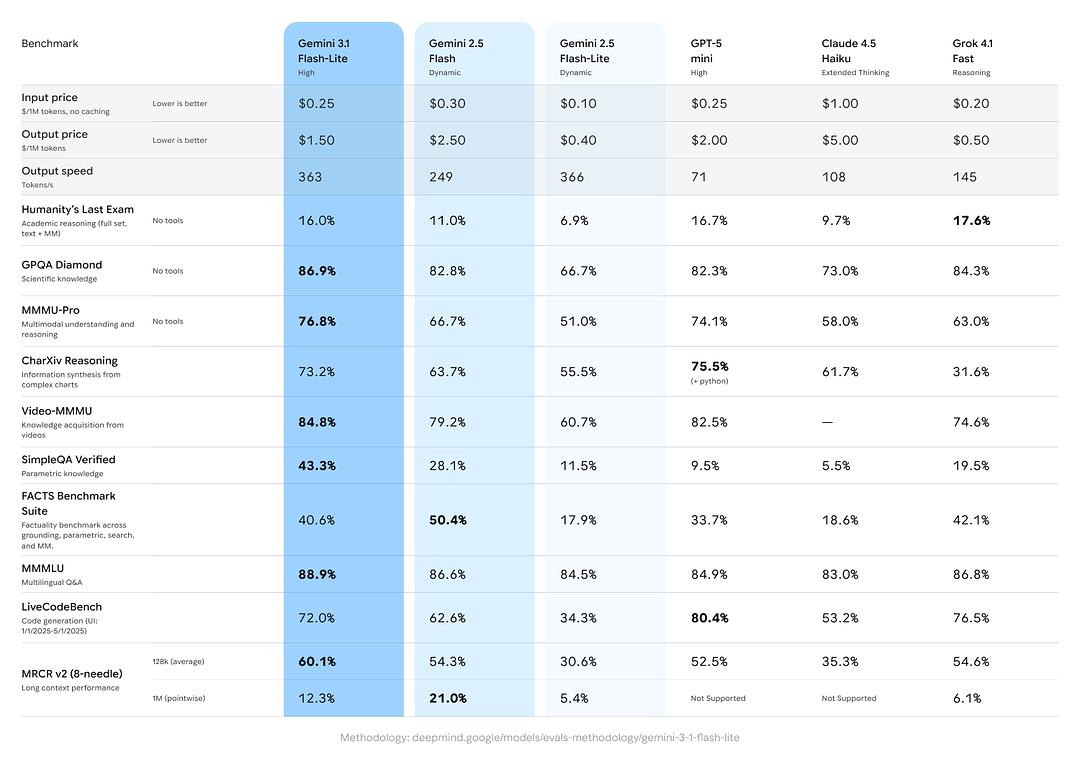
Gemini 3.1 Flash-Lite mengatasi Gemini 2.5 Flash yang lebih lama pada beberapa metrik ini sambil menyampaikan kelajuan/kos yang jauh lebih baik.
Kes penggunaan yang sesuai dengan Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite direka mengikut set beban kerja praktikal yang jelas di mana kadar hantaran tinggi dan kos per token yang lebih rendah adalah penentu:
Ejen perbualan frekuensi tinggi & UI penstriman
Chatbot masa nyata, aliran transkripsi + terjemahan langsung, dan UI kolaboratif yang memaparkan jawapan separa semasa model menjana mendapat manfaat daripada output token penstriman dan masa-ke-token pertama yang rendah oleh Flash-Lite.
Pemprosesan data pukal (RAG, saluran transformasi)
Pengambilan dokumen besar-besaran: pengekstrakan entiti, pelabelan metadata, pengelasan, dan tugas terjemahan ke atas berjuta-juta dokumen — Gemini 3.1 Flash-Lite menurunkan kos inferens sambil menyediakan ketepatan yang boleh diterima untuk output berasaskan templat atau peraturan.
Pengkomputeran gaya edge atau latar belakang
Beban kerja yang memproses telemetri masuk atau data tidak berstruktur secara berterusan (cth., saluran pengelasan moderasi kandungan, penjanaan laporan automatik) sangat sesuai kerana Gemini 3.1 Flash-Lite meminimumkan kos seunit.
Alatan pembangun dan pelengkapan kod kelompok
Untuk ciri seperti rangka berbilang fail, linting kod berskala besar, dan penjanaan templat pada skala, kelebihan kelajuan Gemini 3.1 Flash-Lite mengurangkan latensi dan kos untuk alatan pengalaman pembangun di mana kedalaman penaakulan maksimum mutlak tidak diperlukan.
Membandingkan Gemini 3.1 Flash-Lite dengan model Gemini lain dan pesaing
Dalam keluarga Gemini
- Gemini 3.1 Pro: keupayaan tertinggi pada penaakulan kompleks dan perancangan berbilang langkah; jauh lebih mahal dan lebih perlahan per token tetapi lebih baik untuk tugas bernuansa mendalam.
- Gemini 3.1 Flash (bukan Lite): menyasarkan titik tengah antara kadar hantaran mentah dan keupayaan — Flash-Lite mengoptimumkan lebih jauh pada timbunan pengiraan untuk kadar hantaran.
Berbanding model “pantas” pesaing
Gemini 3.1 Flash-Lite mengatasi atau menyamai beberapa model pantas/mini pada banyak metrik kadar hantaran dan kualiti — namun penganalisis bebas memberi amaran bahawa perbandingan langsung bergantung kepada metodologi penilaian dan pemilihan set data. Jangkakan Gemini 3.1 Flash-Lite sangat kompetitif dari segi kadar hantaran dan kos sambil kekal hampir di pertengahan kelompok pada metrik penaakulan tertinggi.
Kesimpulan — kedudukan Flash-Lite dalam timbunan AI
Gemini 3.1 Flash-Lite ialah satu tawaran yang direka dengan sengaja: ahli keluarga Gemini 3 yang cekap dan berfokus kadar hantaran yang membolehkan pasukan menukar sedikit pengiraan per contoh untuk peningkatan ketara dalam latensi dan kos. Untuk perniagaan dan pembangun yang membina rantaian volum tinggi — terjemahan, pemprosesan kelompok, UI penstriman, dan tugas berasaskan agen berkerumitan sederhana — Flash-Lite mewakili enjin asas yang munasabah. Bagi organisasi yang memerlukan kesetiaan penaakulan setinggi mungkin, model Pro kekal sebagai pilihan yang sesuai.
Jika beban kerja anda didominasi oleh banyak inferens pendek dan berulang atau anda memerlukan output penstriman pantas pada skala besar, Flash-Lite berbaloi untuk dicuba. Jika beban kerja anda bergantung pada penaakulan berbilang hop yang mendalam, rancang pendekatan hibrid: halakan trafik berkapasiti ke Flash-Lite dan eskalasi pertanyaan bernilai tinggi yang kompleks kepada model Pro.
Pembangun boleh mengakses Gemini 3.1 Flash Lite melalui CometAPI sekarang. Untuk bermula, terokai keupayaan model dalam Playground dan rujuk panduan API untuk arahan terperinci. Sebelum mengakses, pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga yang jauh lebih rendah daripada harga rasmi untuk membantu anda melakukan integrasi.
Sedia untuk bermula?→ Daftar untuk Gemini 3.1 Flash lite hari ini !
Jika anda ingin mengetahui lebih banyak petua, panduan dan berita tentang AI ikuti kami di VK, X dan Discord!