Specyfikacja techniczna GLM-5.2
| Pozycja | GLM-5.2 |
|---|---|
| Dostawca | Zhipu AI |
| Data wydania | 13 czerwca 2026 |
| Typ modelu | LLM Mixture-of-Experts (MoE) z otwartymi wagami |
| Łączna liczba parametrów | ~744B |
| Aktywne parametry | ~40B na token |
| Okno kontekstu | 1,000,000 tokenów |
| Maksymalna długość wyjścia | 131,072 tokenów |
| Tryby rozumowania | High, Max |
| Licencja | MIT |
| Główne ukierunkowanie | programowanie agentowe, inżynieria oprogramowania, rozumowanie długoterminowe |
| Dostępność API | platforma Z.ai i kompatybilni dostawcy |
| Otwarte wagi | Tak |
GLM-5.2 to najnowszy flagowy model z rodziny GLM firmy Zhipu AI. W przeciwieństwie do ogólnoprzeznaczeniowych modeli czołowych, GLM-5.2 jest przede wszystkim pozycjonowany jako model zorientowany na kodowanie i agentów, zaprojektowany do inżynierii oprogramowania w skali repozytoriów, autonomicznych przepływów pracy oraz rozumowania w bardzo długim kontekście. Jego kluczową możliwością jest natywne okno kontekstu o rozmiarze 1 milion tokenów, co czyni je jednym z największych publicznie dostępnych okien kontekstu wśród modeli z otwartymi wagami.
Główne funkcje GLM-5.2
- Okno kontekstu 1M tokenów dla całych repozytoriów, obszernych zestawów dokumentacji i wielosesyjnych przepływów pracy agentów.
- Optymalizacja ukierunkowana na kodowanie skoncentrowana na refaktoryzacji, debugowaniu, generowaniu kodu i zadaniach inżynierii oprogramowania.
- Wsparcie agentowych przepływów pracy dla narzędzi takich jak Claude Code, Cline, Roo Code, OpenCode i podobnych agentów do kodowania.
- Wydanie z otwartymi wagami na licencji MIT, umożliwiające samodzielne hostowanie i dostrajanie.
- Dwa tryby rozumowania (High i Max) pozwalające na kompromis między opóźnieniem a głębokością rozumowania.
- Duża architektura MoE z około 744B łącznych parametrów przy aktywowaniu jedynie ~40B na token dla wydajności.
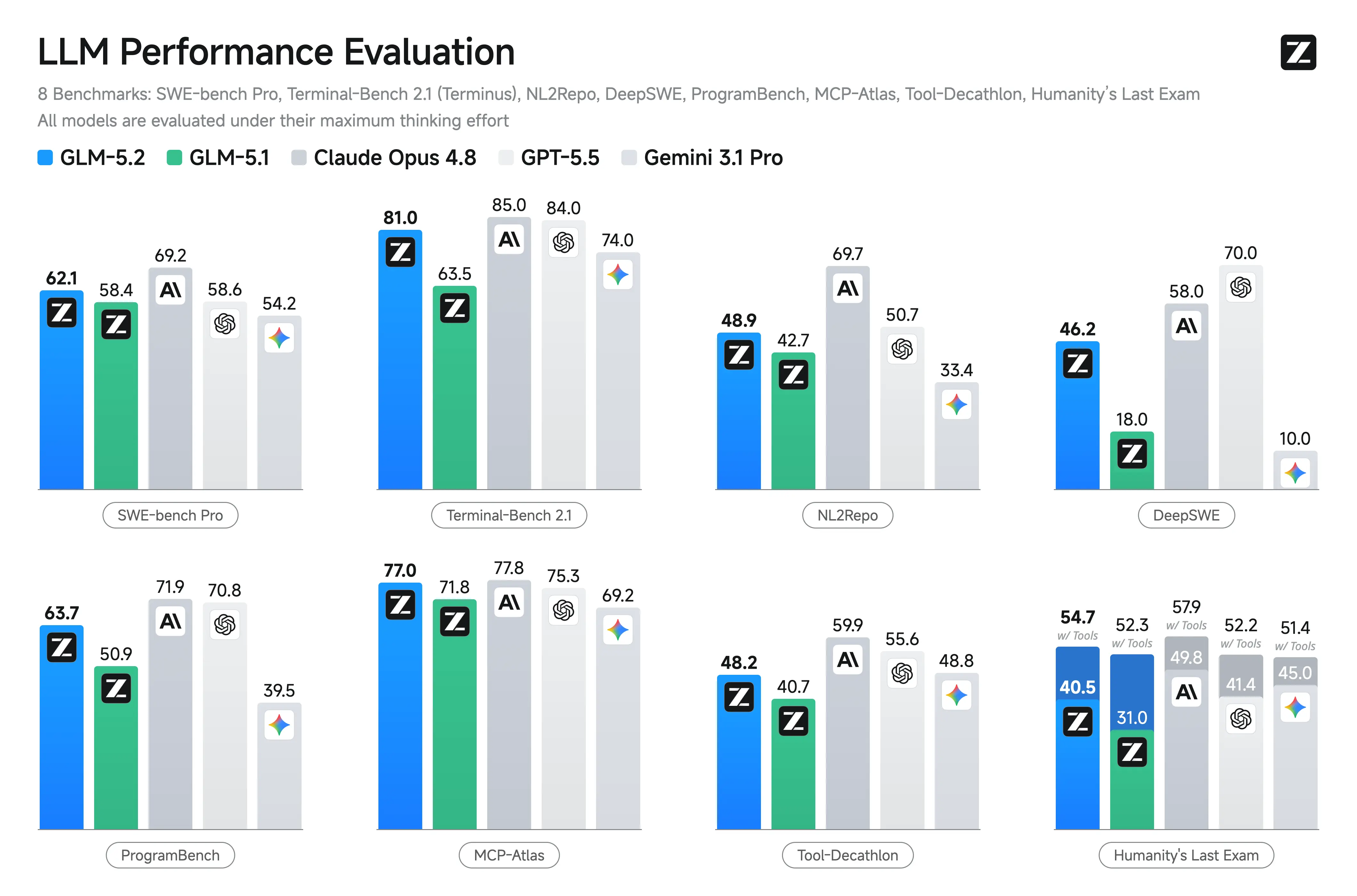
Wyniki benchmarków GLM-5.2
Zhipu nie opublikowało przy premierze kompleksowych oficjalnych wyników benchmarków, co sprawia, że bezpośrednie porównania są mniej pewne niż w przypadku modeli takich jak GPT-5 czy Claude. Wiele raportów branżowych odnotowuje brak niezależnie zweryfikowanych publikacji wyników benchmarków.
| Benchmark | Zgłoszony wynik |
|---|---|
| Terminal-Bench 2.1 | 81.0 |
| SWE-Bench Pro | 62.1 |
| NL2Repo | 48.9 |
| AIME 2026 | 99.2 |
GLM-5.2 vs GLM-5.1 vs Claude Opus 4.8
| Specyfikacja | GLM-5.2 | GLM-5.1 | Claude Opus 4.8 |
|---|---|---|---|
| Data wydania | 2026-06-13 | 2026 | 2026 |
| Okno kontekstu | 1,000,000 | ~200,000 | 1,000,000 |
| Otwarte wagi | Tak (MIT) | Tak | Nie |
| Tryby rozumowania | High, Max | Standard | Extended Thinking |
| Łączna liczba parametrów | 744B | 744B | Nie ujawniono |
| Aktywne parametry | 40B | 40B | Nie ujawniono |
| Oficjalne dane testów porównawczych | Nie opublikowano | Opublikowano przy premierze | Opublikowano |
Główną udokumentowaną zmianą GLM-5.2 względem GLM-5.1 jest rozszerzenie okna kontekstu do 1M tokenów oraz wprowadzenie wybieralnych trybów rozumowania High i Max. Przy premierze Z.ai nie opublikowało oficjalnych wyników SWE-Bench, LiveCodeBench, HumanEval ani podobnych benchmarków, dlatego porównania wydajności względem Claude Opus 4.8, GPT-5, DeepSeek czy Qwen pozostają niezweryfikowane.
W porównaniu z innymi otwartymi modelami, głównym wyróżnikiem GLM-5.2 jest połączenie bardzo dużego okna kontekstu, specjalizacji w kodowaniu oraz licencji MIT. Najmocniejszym atutem jest inżynieria oprogramowania w skali repozytoriów, a nie ogólne aplikacje czatowe.
Dlaczego korzystać z GLM-5.2 przez CometAPI?
CometAPI umożliwia programistom integrację GLM-5.2 przy użyciu tego samego interfejsu, który stosowany jest dla dziesiątek wiodących modeli AI.
Korzyści obejmują:
- Ujedniona autoryzacja u wielu dostawców
- Integracja API kompatybilna z OpenAI
- Uproszczone rozliczenia i zarządzanie użyciem
- Szybkie eksperymentowanie z alternatywnymi modelami
- Łatwe przełączanie między modelami do kodowania, rozumowania, obrazu, audio i wideo
- Mniejsze uzależnienie od dostawcy w systemach produkcyjnych
Niezależnie od tego, czy tworzysz AI IDE, wewnętrznego asystenta inżynierskiego, czy platformę automatyzacji przedsiębiorstwa, CometAPI minimalizuje wysiłek integracyjny, zachowując elastyczność.
Jak uzyskać dostęp do GLM-5.2 API w CometAPI
Rozpocznij pracę z naszym produktem w kilku prostych krokach...
Krok 1: Zarejestruj się, aby uzyskać klucz GLM-5.2 API
Utwórz konto na Kie.ai i przejdź do pulpitu API, aby wygenerować swój klucz GLM-5.2 API. Ten klucz uwierzytelnia wszystkie Twoje żądania i daje natychmiastowy dostęp do pełnych możliwości GLM-5.2 API, w tym okna kontekstu 1M tokenów i 128k tokenów wyjściowych.
Krok 2: Wysyłaj żądania do GLM-5.2 API
Użyj swojego klucza GLM-5.2 API, aby wysyłać żądania POST do endpointu Kie.ai. Przekaż swój prompt, ustaw parametry modelu, takie jak poziom wysiłku i maksymalna liczba tokenów, a GLM-5.2 API przetworzy Twoje żądanie — obsługując wszystko od generowania kodu po analizę dokumentów i agentowe użycie narzędzi.
Krok 3: Pobierz wyniki i zintegruj GLM-5.2 API
GLM-5.2 API dostarcza ustrukturyzowane odpowiedzi, w tym tekst uzupełnień, instrukcje wywoływania narzędzi i metadane użycia tokenów. Obsługuje zarówno standardowe odpowiedzi synchroniczne, jak i strumieniowanie w czasie rzeczywistym przez Server-Sent Events (SSE), gdy skonfigurowano stream: true. Endpoint można łatwo zintegrować z istniejącymi przepływami pracy przy użyciu standardowych klientów HTTP lub openAI kompatybilnych SDK, kierując żądania przez url(//api.cometapi.com/v1) z Twoim Bearer Token.