

GPT-5.2 คือรุ่นย่อยประจำเดือนธันวาคม 2025 ของ OpenAI ในตระกูล GPT-5: ตระกูลโมเดลมัลติโหมดระดับเรือธง (ข้อความ + ภาพ + เครื่องมือ) ที่ปรับจูนเพื่อการทำงานความรู้เชิงมืออาชีพ บริบทยาว การใช้เครื่องมือแบบเชิงตัวแทน (agentic) และวิศวกรรมซอฟต์แวร์ OpenAI วางตำแหน่ง GPT-5.2 ว่าเป็นโมเดลในซีรีส์ GPT-5 ที่ทรงพลังที่สุดจนถึงปัจจุบัน และระบุว่าพัฒนาโดยเน้นการให้เหตุผลหลายขั้นตอนที่เชื่อถือได้ การจัดการเอกสารขนาดใหญ่มาก และความปลอดภัย/การปฏิบัติตามนโยบายที่ดีขึ้น; รุ่นนี้มาพร้อม 3 สายผลิตภัณฑ์สำหรับผู้ใช้ — Instant, Thinking และ Pro — และกำลังทยอยปล่อยให้ผู้ใช้ ChatGPT แบบชำระเงินและลูกค้า API ก่อน
GPT-5.2 คืออะไร และทำไมจึงสำคัญ?
GPT-5.2 คือสมาชิกล่าสุดในตระกูล GPT-5 — โมเดล “แนวหน้า” ชุดใหม่ที่ออกแบบมาเพื่อลดช่องว่างระหว่างผู้ช่วยสนทนาแบบครั้งเดียว กับระบบที่ต้องให้เหตุผลข้ามเอกสารยาว เรียกใช้เครื่องมือ ตีความภาพ และดำเนินเวิร์กโฟลว์หลายขั้นตอนอย่างเชื่อถือได้ OpenAI วาง GPT-5.2 เป็นรุ่นที่มีความสามารถสูงสุดสำหรับงานความรู้ระดับมืออาชีพ: ทำสถิติใหม่ในชุดทดสอบภายใน (โดยเฉพาะ GDPval สำหรับงานความรู้) แสดงประสิทธิภาพการเขียนโค้ดที่แข็งแกร่งขึ้นในชุดทดสอบวิศวกรรมซอฟต์แวร์ และมีความสามารถบริบทยาวและด้านภาพที่ดีขึ้นอย่างมีนัยสำคัญ
ในทางปฏิบัติ GPT-5.2 ไม่ใช่แค่ “โมเดลแชตที่ใหญ่ขึ้น” แต่มาเป็นครอบครัว 3 รุ่นย่อย (Instant, Thinking, Pro) ที่แลกเปลี่ยนระหว่างเวลาแฝง ความลึกในการให้เหตุผล และต้นทุน — ซึ่งเมื่อใช้ร่วมกับ API และระบบการจัดเส้นทางของ ChatGPT สามารถใช้สำหรับงานวิจัยยาว ๆ สร้างเอเจนต์ที่เรียกเครื่องมือภายนอก ตีความภาพและชาร์ตซับซ้อน และสร้างโค้ดระดับการผลิตที่แม่นยำกว่ารุ่นก่อน โมเดลรองรับหน้าต่างบริบทขนาดใหญ่มาก (เอกสาร OpenAI ระบุหน้าต่าง 400,000 โทเคน และขีดจำกัดผลลัพธ์สูงสุด 128,000 สำหรับรุ่นเรือธง) มีคุณสมบัติ API ใหม่สำหรับกำหนดระดับความพยายามในการให้เหตุผลอย่างชัดเจน และพฤติกรรมการเรียกใช้เครื่องมือแบบ “agentic”
5 ความสามารถหลักที่ได้รับการอัปเกรดใน GPT-5.2
1) GPT-5.2 เก่งตรรกะหลายขั้นตอนและคณิตศาสตร์ขึ้นหรือไม่?
GPT-5.2 มีความสามารถในการให้เหตุผลแบบหลายขั้นตอนที่คมขึ้น และเห็นได้ชัดว่าดีขึ้นในการแก้ปัญหาทางคณิตศาสตร์และโครงสร้างที่เป็นระบบ OpenAI ระบุว่าได้เพิ่มการควบคุมที่ละเอียดขึ้นสำหรับระดับความพยายามในการให้เหตุผล (ระดับใหม่อย่างเช่น xhigh) รองรับ “โทเคนสำหรับการให้เหตุผล” และปรับจูนโมเดลให้คงลำดับการคิด (chain-of-thought) ได้นานขึ้นในกระบวนการให้เหตุผลภายใน ชุดทดสอบอย่าง FrontierMath และการทดสอบแนว ARC-AGI แสดงให้เห็นถึงการพัฒนาอย่างมีนัยสำคัญเมื่อเทียบกับ GPT-5.1; มีช่องว่างที่มากขึ้นในชุดทดสอบเฉพาะโดเมนที่ใช้ในเวิร์กโฟลว์ด้านวิทยาศาสตร์และการเงิน กล่าวโดยสรุป: GPT-5.2 “คิดนานขึ้น” เมื่อถูกขอ และสามารถทำงานเชิงสัญลักษณ์/คณิตศาสตร์ที่ซับซ้อนมากขึ้นด้วยความสม่ำเสมอที่ดีขึ้น

| RC-AGI-1 (Verified) การให้เหตุผลเชิงนามธรรม | 86.2% | 72.8% |
|---|---|---|
| ARC-AGI-2 (Verified) การให้เหตุผลเชิงนามธรรม | 52.9% | 17.6% |
GPT-5.2 Thinking ทำสถิติในหลายชุดทดสอบเหตุผลเชิงวิทยาศาสตร์และคณิตศาสตร์ขั้นสูง:
- GPQA Diamond Science Quiz: 92.4% (รุ่น Pro 93.2%)
- ARC-AGI-1 Abstract Reasoning: 86.2% (โมเดลแรกที่ทะลุเกณฑ์ 90%)
- ARC-AGI-2 Higher Order Reasoning: 52.9% ทำสถิติใหม่สำหรับโมเดล Thinking Chain
- FrontierMath Advanced Mathematics Test: 40.3% สูงกว่ารุ่นก่อนมาก;
- HMMT ข้อสอบแข่งขันคณิตศาสตร์: 99.4%
- AIME ข้อสอบคณิตศาสตร์: 100% Complete Solution
ยิ่งไปกว่านั้น GPT-5.2 Pro (High) เป็นระดับแนวหน้าใน ARC-AGI-2 โดยทำคะแนนได้ 54.2% ด้วยต้นทุน $15.72 ต่อภารกิจ! เหนือกว่าทุกโมเดลอื่น
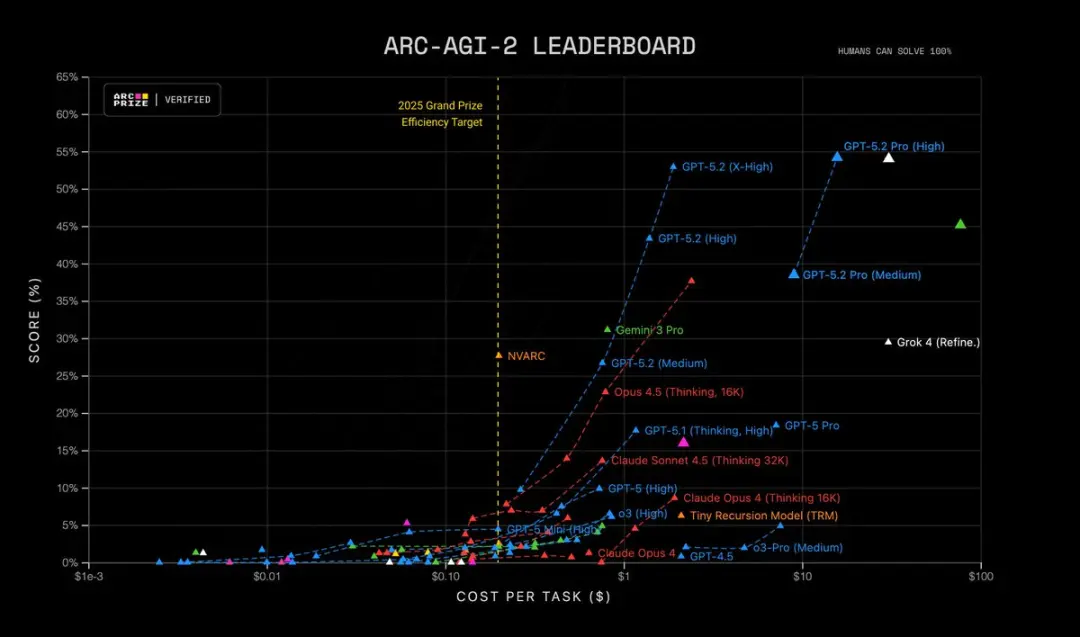
เหตุผลที่สำคัญ: งานจริงจำนวนมาก — แบบจำลองทางการเงิน การออกแบบการทดลอง การสังเคราะห์โปรแกรมที่ต้องใช้เหตุผลเชิงรูปแบบ — ถูกจำกัดด้วยความสามารถของโมเดลในการเชื่อมโยงหลายขั้นตอนอย่างถูกต้อง GPT-5.2 ลด “ขั้นตอนที่แต่งขึ้น” และให้ร่องรอยการให้เหตุผลระหว่างทางที่นิ่งขึ้นเมื่อคุณขอให้แสดงวิธีทำงาน
2) ความเข้าใจข้อความยาวและการให้เหตุผลข้ามเอกสารดีขึ้นอย่างไร?
ความเข้าใจบริบทยาวเป็นหนึ่งในไฮไลต์ GPT-5.2 รองรับหน้าต่างบริบท 400k โทเคน และที่สำคัญคือคงความแม่นยำได้สูงเมื่อเนื้อหาที่เกี่ยวข้องอยู่ลึกเข้าไปในบริบทนั้น GDPval ชุดงานสำหรับ “งานความรู้ที่กำหนดข้อกำหนดอย่างดี” ครอบคลุม 44 อาชีพ ซึ่ง GPT-5.2 Thinking ทำได้ทัดเทียมหรือดีกว่าผู้เชี่ยวชาญมนุษย์ในสัดส่วนงานจำนวนมาก รายงานอิสระยืนยันว่าโมเดลรักษาและสังเคราะห์ข้อมูลข้ามเอกสารจำนวนมากได้ดีกว่ารุ่นก่อนอย่างมาก นี่คือก้าวที่ใช้งานได้จริงสำหรับงานอย่างตรวจสอบสถานะ สรุปทางกฎหมาย ทบทวนวรรณกรรม และทำความเข้าใจโค้ดเบสขนาดใหญ่
GPT-5.2 สามารถจัดการบริบทได้ถึง 256,000 โทเคน (ประมาณ 200+ หน้าเอกสาร) นอกจากนี้ ในการทดสอบความเข้าใจข้อความยาว "OpenAI MRCRv2" GPT-5.2 Thinking ทำความแม่นยำได้ใกล้ 100%
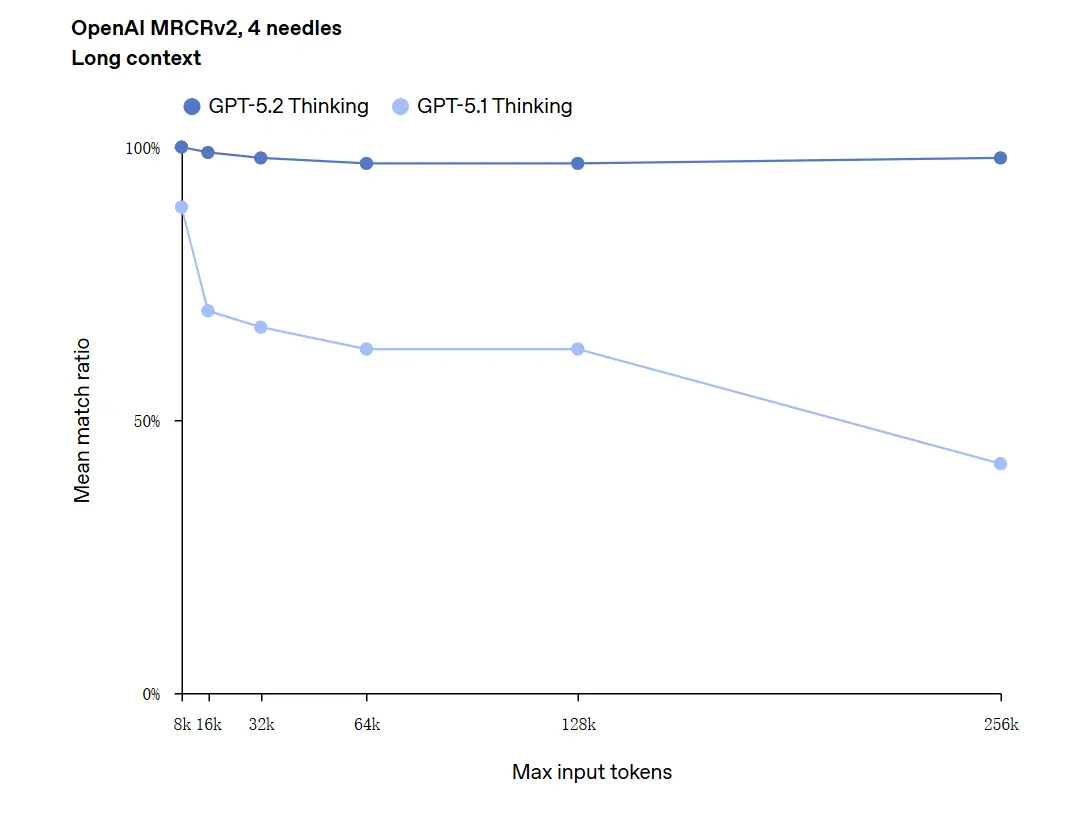
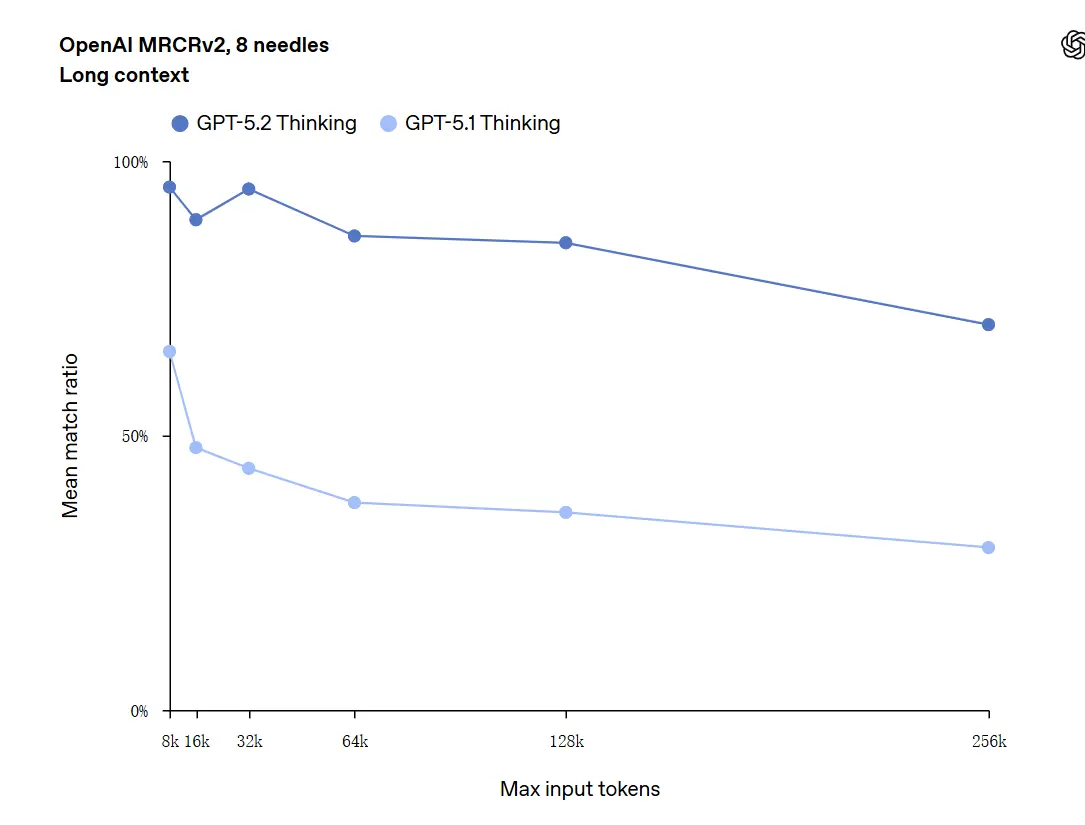
ข้อควรระวังเกี่ยวกับ “ความแม่นยำ 100%”: คำอธิบายของการพัฒนาคือ “เข้าใกล้ 100%” สำหรับไมโครทาสก์ที่แคบ ข้อมูลของ OpenAI จึงควรอธิบายว่า “ระดับแนวหน้าหรือเทียบเท่าหรือเหนือกว่าผู้เชี่ยวชาญมนุษย์ในงานที่ประเมิน” ไม่ใช่ไร้ที่ติในทุกการใช้งาน ชุดทดสอบแสดงการพัฒนามาก แต่ไม่ใช่สมบูรณ์แบบในทุกกรณี
3) ความเข้าใจด้านภาพและการให้เหตุผลแบบมัลติโหมดมีอะไรใหม่?
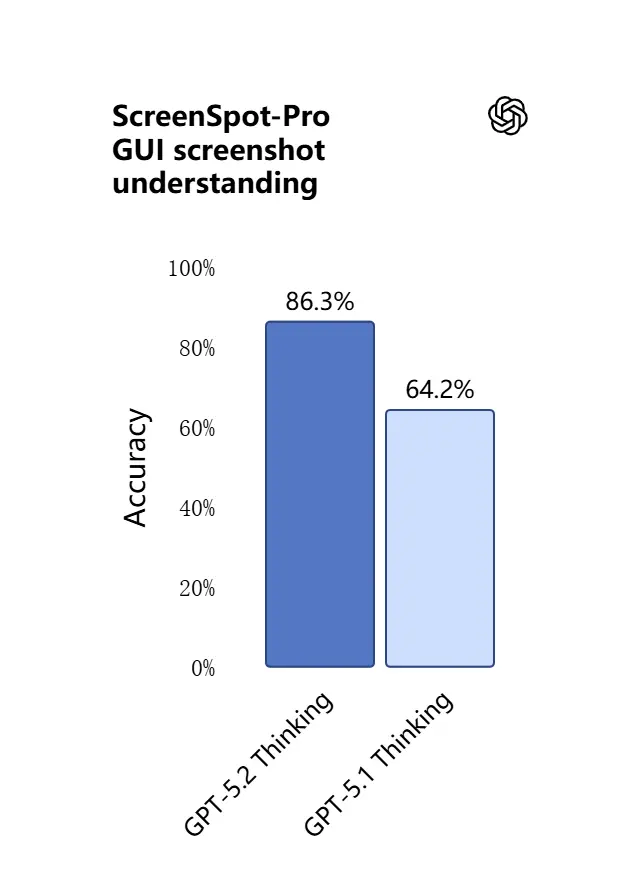
ความสามารถด้านภาพใน GPT-5.2 คมขึ้นและใช้งานได้จริงยิ่งกว่าเดิม โมเดลตีความภาพหน้าจอ อ่านชาร์ตและตาราง ระบุองค์ประกอบ UI และผสมผสานข้อมูลภาพกับบริบทข้อความยาวได้ดีขึ้น ไม่ใช่แค่การบรรยายภาพ: GPT-5.2 สามารถดึงข้อมูลเชิงโครงสร้างจากภาพ (เช่น ตารางใน PDF) อธิบายกราฟ และให้เหตุผลกับไดอะแกรมในแบบที่รองรับการกระทำกับเครื่องมือต่อเนื่อง (เช่น สร้างสเปรดชีตจากรายงานที่ถ่ายภาพมา)
.webp)
ผลในทางปฏิบัติ: ทีมสามารถป้อนชุดสไลด์ รายงานวิจัยสแกน หรือเอกสารที่มีภาพจำนวนมากเข้าสู่โมเดลโดยตรง และขอการสังเคราะห์ข้ามเอกสาร — ลดงานดึงข้อมูลด้วยมืออย่างมาก
4) การเรียกใช้เครื่องมือและการดำเนินงานภารกิจเปลี่ยนไปอย่างไร?
GPT-5.2 ก้าวลึกสู่พฤติกรรมเชิงเอเจนต์มากขึ้น: วางแผนงานหลายขั้นตอน ตัดสินใจว่าเมื่อไรควรเรียกเครื่องมือภายนอก และดำเนินชุดการเรียก API/เครื่องมือเพื่อจบงานแบบ end-to-end ได้ดีกว่ารุ่นก่อน การปรับปรุง “agentic tool-calling” — โมเดลจะเสนอแผน เรียกเครื่องมือ (ฐานข้อมูล คอมพิวต์ ระบบไฟล์ เบราว์เซอร์ ตัวรันโค้ด) และสังเคราะห์ผลลัพธ์เป็นงานส่งมอบสุดท้ายได้เชื่อถือมากขึ้นกว่าเดิม API มีระบบการจัดเส้นทางและการควบคุมความปลอดภัย (รายการเครื่องมือที่อนุญาต โครงร่างการเรียกเครื่องมือ) และ UI ของ ChatGPT สามารถจัดเส้นทางคำขอไปยังรุ่นย่อย 5.2 ที่เหมาะสม (Instant เทียบกับ Thinking) โดยอัตโนมัติ
GPT-5.2 ทำคะแนน 98.7% ในชุดทดสอบ Tau2-Bench Telecom แสดงความสามารถการเรียกใช้เครื่องมือที่เติบโตเต็มที่ในงานสนทนาหลายรอบที่ซับซ้อน
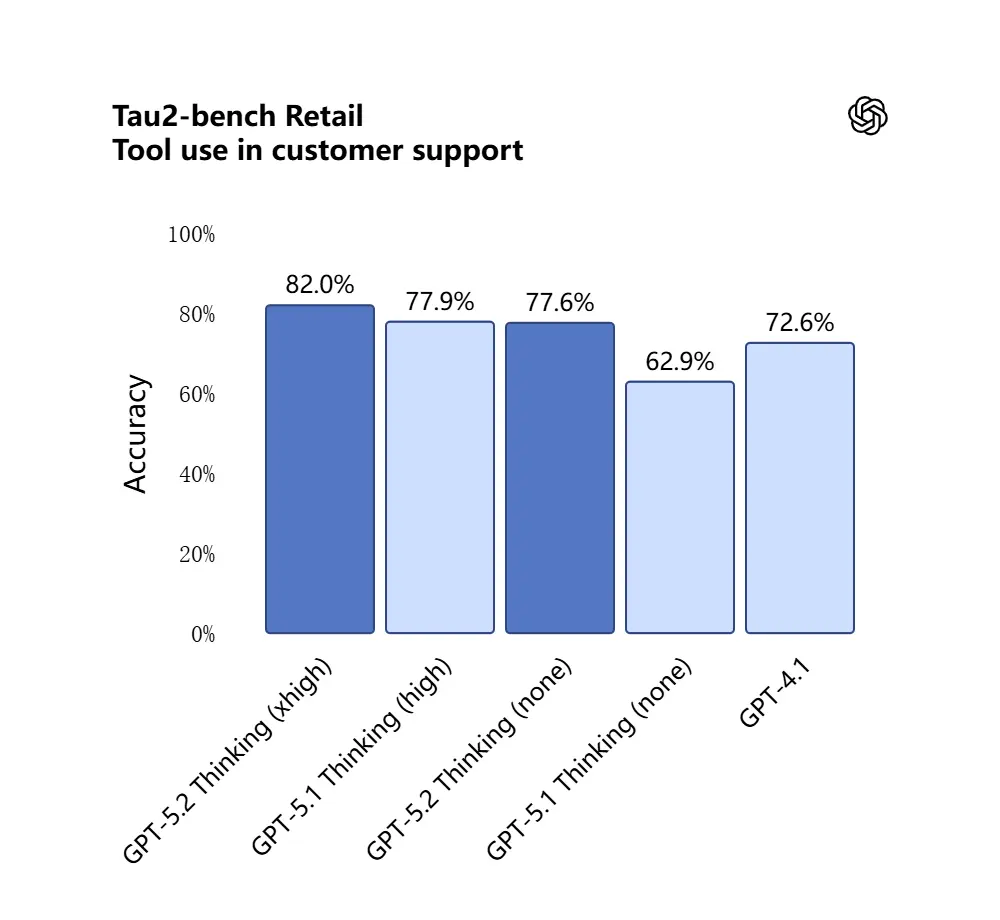
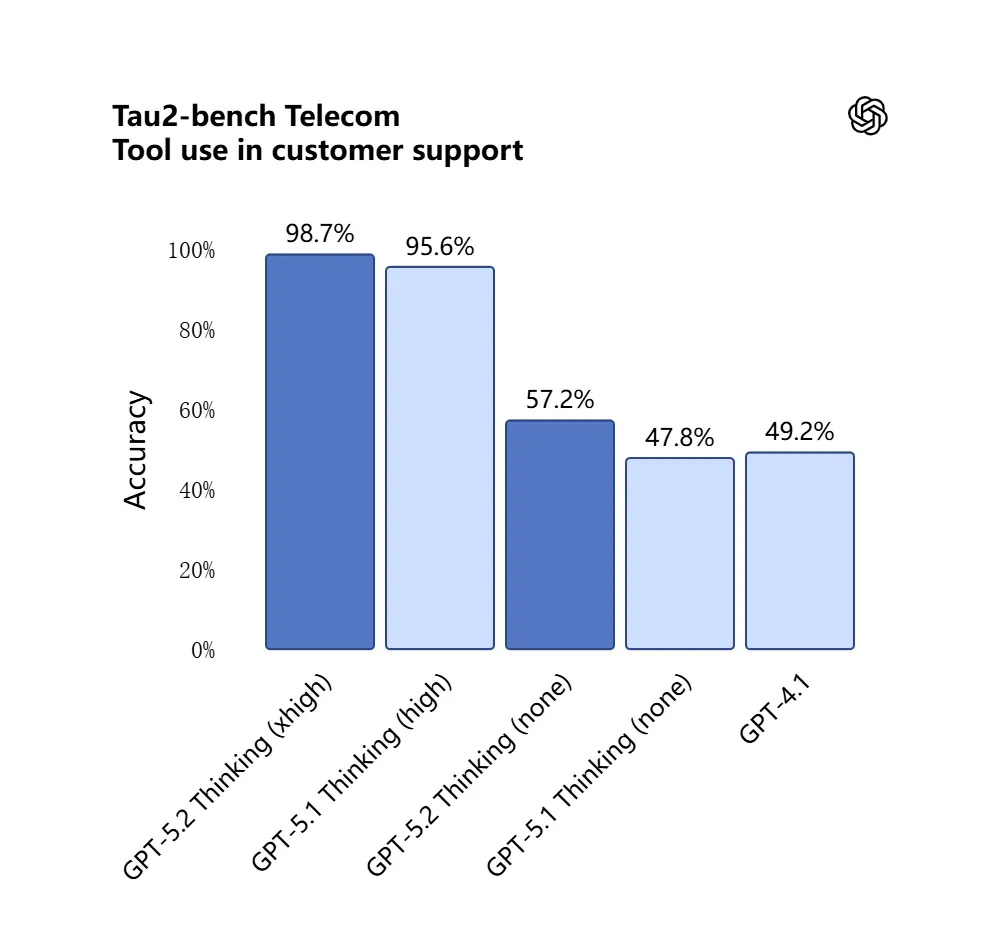
เหตุผลที่สำคัญ: สิ่งนี้ทำให้ GPT-5.2 มีประโยชน์มากขึ้นในฐานะผู้ช่วยอัตโนมัติสำหรับเวิร์กโฟลว์อย่าง “นำเข้าสัญญาเหล่านี้ ดึงข้อกำหนด อัปเดตสเปรดชีต และเขียนอีเมลสรุป” — งานที่ก่อนหน้านี้ต้องอาศัยการออกแบบลำดับอย่างระมัดระวัง
5) ความสามารถด้านการเขียนโปรแกรมได้รับการพัฒนา
GPT-5.2 ดีขึ้นอย่างชัดเจนในงานวิศวกรรมซอฟต์แวร์: เขียนโมดูลที่ครบถ้วนขึ้น สร้างและรันทดสอบได้เชื่อถือขึ้น เข้าใจกราฟความขึ้นต่อกันของโปรเจ็กต์ที่ซับซ้อน และมีแนวโน้ม “ขี้เกียจเขียนโค้ด” น้อยลง (ไม่ข้ามโค้ดบอยเลอร์เพลตหรือไม่เชื่อมต่อโมดูล) ในชุดทดสอบโค้ดระดับอุตสาหกรรม (เช่น SWE-bench Pro) GPT-5.2 ทำสถิติใหม่ สำหรับทีมที่ใช้ LLM เป็นคู่เขียนโปรแกรม การปรับปรุงนี้ช่วยลดงานตรวจสอบและแก้ไขด้วยมือหลังการสร้าง
ในการทดสอบ SWE-Bench Pro (งานวิศวกรรมซอฟต์แวร์ในโลกจริงระดับอุตสาหกรรม) คะแนนของ GPT-5.2 Thinking เพิ่มขึ้นเป็น 55.6% และยังทำสถิติใหม่ 80% ในการทดสอบ SWE-Bench Verified
_Software%20engineering.webp)
ในทางปฏิบัติ หมายความว่า:
- การดีบักโค้ดในสภาพแวดล้อม production อัตโนมัติทำให้เสถียรมากขึ้น;
- รองรับการเขียนโปรแกรมหลายภาษา (ไม่จำกัดแค่ Python);
- สามารถทำงานซ่อมแซมแบบ end-to-end ได้ด้วยตนเอง
GPT-5.2 ต่างจาก GPT-5.1 อย่างไร?
คำตอบสั้น: GPT-5.2 คือการอัปเกรดแบบวนรอบแต่มีนัยสำคัญ ยังคงสถาปัตยกรรมและฐานมัลติโหมดของตระกูล GPT-5 แต่ก้าวหน้าใน 4 มิติที่ใช้งานได้จริง:
- ความลึกและความสม่ำเสมอของการให้เหตุผล: 5.2 แนะนำระดับความพยายามในการให้เหตุผลที่สูงขึ้นและเชื่อมโยงขั้นตอนสำหรับปัญหาหลายขั้นตอนดีขึ้น; 5.1 เคยปรับปรุงการให้เหตุผลมาก่อน แต่ 5.2 ยกระดับเพดานสำหรับคณิตศาสตร์ซับซ้อนและตรรกะหลายช่วง
- ความเชื่อถือได้ในบริบทยาว: ทั้งสองรุ่นขยายบริบท แต่ 5.2 ปรับจูนให้คงความแม่นยำลึกเข้าไปในอินพุตที่ยาวมาก (OpenAI อ้างการคงรักษาข้อมูลดีขึ้นถึงหลายแสนโทเคน)
- ความเที่ยงตรงของภาพ + มัลติโหมด: 5.2 ปรับปรุงการอ้างอิงข้ามระหว่างภาพกับข้อความ — เช่น อ่านชาร์ตและบูรณาการข้อมูลนั้นลงในสเปรดชีต — ทำให้งานสำเร็จที่ระดับภารกิจแม่นยำขึ้น
- พฤติกรรมการใช้เครื่องมือเชิงเอเจนต์และคุณสมบัติ API: 5.2 เปิดเผยพารามิเตอร์ระดับความพยายามในการให้เหตุผล (
xhigh) และคุณสมบัติการบีบอัดบริบทใน API และ OpenAI ปรับปรุงตรรกะการจัดเส้นทางใน ChatGPT เพื่อให้ UI เลือกรุ่นย่อยที่เหมาะที่สุดโดยอัตโนมัติ - ข้อผิดพลาดน้อยลง เสถียรภาพมากขึ้น: GPT-5.2 ลด “อัตราภาพหลอน” (อัตราการตอบเท็จ) ลง 38% ตอบคำถามด้านวิจัย การเขียน และการวิเคราะห์ได้เชื่อถือขึ้น ลดกรณี “ข้อเท็จจริงที่แต่งขึ้น” ในงานที่ซับซ้อน เอาต์พุตเชิงโครงสร้างชัดเจนขึ้น และตรรกะนิ่งขึ้น ขณะเดียวกัน ความปลอดภัยของการตอบสนองดีขึ้นอย่างมากในงานที่เกี่ยวข้องกับสุขภาพจิต ทำงานได้แข็งแรงขึ้นในบริบทอ่อนไหว เช่น สุขภาพจิต การทำร้ายตนเอง การฆ่าตัวตาย และการพึ่งพาทางอารมณ์
ในการประเมินระบบ GPT-5.2 Instant ทำคะแนน 0.995 (เต็ม 1.0) ในงาน “การสนับสนุนสุขภาพจิต” สูงกว่า GPT-5.1 (0.883) อย่างมีนัยสำคัญ
ในเชิงปริมาณ ชุดทดสอบที่ OpenAI เผยแพร่แสดงการพัฒนาที่จับต้องได้บน GDPval ชุดทดสอบคณิตศาสตร์ (FrontierMath) และการประเมินวิศวกรรมซอฟต์แวร์ GPT-5.2 เหนือกว่า GPT-5.1 ในงานสเปรดชีตระดับนักวิเคราะห์สาย investment banking อยู่หลายเปอร์เซ็นต์
GPT-5.2 ใช้ฟรีไหม — ราคาเท่าไร?
ฉันสามารถใช้ GPT-5.2 ได้ฟรีหรือไม่?
OpenAI เริ่มปล่อย GPT-5.2 ให้กับแผน ChatGPT แบบชำระเงินและการเข้าถึง API ก่อน ตามปกติ OpenAI จะเก็บโมเดลที่เร็ว/ลึกที่สุดไว้ในชั้นชำระเงิน และเปิดรุ่นเบากว่าให้กว้างขึ้นในภายหลัง; สำหรับ 5.2 บริษัทระบุว่าจะเริ่มปล่อยในแผนแบบชำระเงิน (Plus, Pro, Business, Enterprise) และเปิด API ให้นักพัฒนา นั่นหมายความว่าการเข้าถึงฟรีทันทีมักจำกัด: ชั้นฟรีอาจได้เข้าถึงแบบลดทอนหรือถูกจัดเส้นทาง (เช่น ไปยังรุ่นย่อยที่เบากว่า) ภายหลังเมื่อ OpenAI ขยายการปล่อย
ข่าวดีคือ CometAPI ผสานกับ GPT-5.2 แล้ว และตอนนี้กำลังจัดโปรโมชันคริสต์มาส คุณสามารถใช้ GPT-5.2 ผ่าน CometAPI ได้ โดยมี playground ให้ทดลองโต้ตอบกับ GPT-5.2 ได้ฟรี และนักพัฒนาสามารถใช้ GPT-5.2 API (CometAPI คิดราคาเพียง 20% ของ OpenAI) เพื่อสร้างเวิร์กโฟลว์
ใช้ผ่าน API มีค่าใช้จ่ายเท่าไร (นักพัฒนา/การใช้งานผลิตจริง)?
การใช้งาน API คิดค่าบริการตามจำนวนโทเคน ข้อมูลราคาแพลตฟอร์มที่ OpenAI เผยแพร่ตอนเปิดตัวระบุว่า (CometAPI คิดราคาเพียง 20% ของ OpenAI):
- GPT-5.2 (standard chat) — $1.75 ต่อ 1M โทเคนขาเข้า และ $14 ต่อ 1M โทเคนขาออก (มีส่วนลดสำหรับอินพุตที่แคช)
- GPT-5.2 Pro (flagship) — $21 ต่อ 1M โทเคนขาเข้า และ $168 ต่อ 1M โทเคนขาออก (แพงกว่ามากเพราะมุ่งสำหรับงานที่ต้องการความแม่นยำสูงและใช้คอมพิวต์หนัก)
- เมื่อเทียบกับ GPT-5.1 จะถูกกว่า (เช่น $1.25 ขาเข้า / $10 ขาออก ต่อ 1M โทเคน)
คำตีความ: ค่าใช้จ่าย API เพิ่มขึ้นเมื่อเทียบกับรุ่นก่อน ราคาเป็นสัญญาณว่า ประสิทธิภาพการให้เหตุผลระดับพรีเมียมและบริบทยาวของ 5.2 ถูกวางเป็นระดับผลิตภัณฑ์ที่แยกต่างหาก สำหรับระบบผลิตจริง ต้นทุนแผนจะขึ้นกับจำนวนโทเคนขาเข้า/ขาออกและความถี่ในการใช้อินพุตที่แคช (อินพุตที่แคชได้ส่วนลดมาก)
แล้วในทางปฏิบัติหมายความว่าอย่างไร
- สำหรับการใช้งานทั่วไปผ่าน UI ของ ChatGPT แผนสมัครรายเดือน (Plus, Pro, Business, Enterprise) คือเส้นทางหลัก ราคาแผนสมาชิกไม่เปลี่ยนพร้อมการปล่อย 5.2 (OpenAI มักตรึงราคาแผนแม้ว่ารายการโมเดลจะเปลี่ยน)
- สำหรับการใช้งานผลิตจริงและนักพัฒนา ให้ตั้งงบตามโทเคน หากแอปของคุณสตรีมคำตอบยาวมากหรือประมวลเอกสารยาว ราคาโทเคนขาออก ($14 / 1M โทเคนสำหรับ Thinking) จะเป็นสัดส่วนหลัก เว้นแต่คุณจะจัดการแคชอินพุตและนำผลลัพธ์กลับมาใช้ซ้ำอย่างรอบคอบ
GPT-5.2 Instant vs GPT-5.2 Thinking vs GPT-5.2 Pro
OpenAI เปิดตัว GPT-5.2 พร้อม 3 รุ่นย่อยที่ตั้งใจจับคู่กับการใช้งาน: Instant, Thinking และ Pro:
- GPT-5.2 Instant: รวดเร็ว คุ้มค่า ปรับจูนเพื่อการทำงานประจำวัน — คำถามที่พบบ่อย คู่มือ แปลภาษา ร่างแบบเร็ว เวลาแฝงต่ำ เหมาะกับร่างแรกและเวิร์กโฟลว์ง่ายๆ
- GPT-5.2 Thinking: คำตอบลึกและคุณภาพสูงสำหรับงานต่อเนื่อง — สรุปเอกสารยาว วางแผนหลายขั้นตอน รีวิวโค้ดละเอียด สมดุลเวลาแฝงกับคุณภาพ; เป็น “ม้าทำงาน” สำหรับงานมืออาชีพ
- GPT-5.2 Pro: คุณภาพและความน่าเชื่อถือสูงสุด ช้ากว่าและแพงกว่า เหมาะกับงานยาก เสี่ยงสูง (วิศวกรรมซับซ้อน การสังเคราะห์ทางกฎหมาย การตัดสินใจมูลค่าสูง) และสถานการณ์ที่ต้องการระดับความพยายามในการให้เหตุผล ‘xhigh’
ตารางเปรียบเทียบ
| คุณสมบัติ / ตัวชี้วัด | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|
| การใช้งานที่ตั้งใจออกแบบ | งานประจำวัน ร่างเร็ว | การวิเคราะห์ลึก เอกสารยาว | คุณภาพสูงสุด ปัญหาซับซ้อน |
| เวลาแฝง | ต่ำสุด | ปานกลาง | สูงสุด |
| ระดับความพยายามให้เหตุผล | มาตรฐาน | สูง | มี xHigh |
| ดีที่สุดสำหรับ | FAQ, บทเรียน, แปล, พรอมต์สั้น | สรุป วางแผน สเปรดชีต งานโค้ด | วิศวกรรมซับซ้อน สังเคราะห์ทางกฎหมาย งานวิจัย |
| ตัวอย่างชื่อ API | gpt-5.2-chat-latest | gpt-5.2 | gpt-5.2-pro |
| ราคาโทเคนขาเข้า (API) | $1.75 / 1M | $1.75 / 1M | $21 / 1M |
| ราคาโทเคนขาออก (API) | $14 / 1M | $14 / 1M | $168 / 1M |
| การพร้อมใช้งาน (ChatGPT) | ทยอยปล่อย; แผนชำระเงินก่อน แล้วกว้างขึ้น | ทยอยปล่อยให้แผนชำระเงิน | ผู้ใช้ Pro / Enterprise (ชำระเงิน) |
| ตัวอย่างกรณีใช้งาน | ร่างอีเมล โค้ดสั้นๆ | สร้างแบบจำลองการเงินหลายชีต ถาม-ตอบรายงานยาว | ตรวจสอบโค้ดเบส สร้างดีไซน์ระบบระดับผลิตจริง |
ใครเหมาะที่จะใช้ GPT-5.2?
GPT-5.2 ถูกออกแบบมาสำหรับผู้ใช้เป้าหมายที่หลากหลาย ด้านล่างคือคำแนะนำตามบทบาท:
องค์กรและทีมผลิตภัณฑ์
หากคุณสร้างผลิตภัณฑ์งานความรู้ (ผู้ช่วยวิจัย ตรวจสัญญา ไปป์ไลน์วิเคราะห์ หรือเครื่องมือสำหรับนักพัฒนา) ความสามารถบริบทยาวและเชิงเอเจนต์ของ GPT-5.2 สามารถลดความซับซ้อนการผสานรวมได้อย่างมาก องค์กรที่ต้องการความเข้าใจเอกสารที่แข็งแรง รายงานอัตโนมัติ หรือโคไพล็อตอัจฉริยะจะพบว่า Thinking/Pro มีประโยชน์ Microsoft และพันธมิตรแพลตฟอร์มอื่นกำลังผสาน 5.2 เข้ากับชุดเพิ่มผลิตภาพ (เช่น Microsoft 365 Copilot)
นักพัฒนาและทีมวิศวกรรม
ทีมที่ต้องการใช้ LLM เป็นคู่เขียนโปรแกรมหรืออัตโนมัติการสร้าง/ทดสอบโค้ดจะได้ประโยชน์จากความเที่ยงตรงการเขียนโปรแกรมที่ดีขึ้นใน 5.2 การเข้าถึง API (โหมด thinking หรือ pro) เปิดโอกาสการสังเคราะห์เชิงลึกของโค้ดเบสขนาดใหญ่ด้วยหน้าต่างบริบท 400k โทเคน คาดว่าต้นทุน API จะสูงขึ้นเมื่อใช้ Pro แต่การลดงานดีบักและรีวิวด้วยมืออาจคุ้มสำหรับระบบที่ซับซ้อน
นักวิจัยและนักวิเคราะห์เชิงข้อมูล
หากคุณสังเคราะห์วรรณกรรมเป็นประจำ แยกรายงานเทคนิคยาว หรืออยากได้การช่วยออกแบบการทดลอง ความสามารถบริบทยาวและคณิตศาสตร์ของ GPT-5.2 ช่วยเร่งเวิร์กโฟลว์ได้ สำหรับงานที่ทำซ้ำได้ จับคู่โมเดลกับพรอมต์ที่ออกแบบอย่างระมัดระวังและขั้นตอนตรวจสอบ
ธุรกิจขนาดเล็กและผู้ใช้ระดับสูง
ChatGPT Plus (และ Pro สำหรับผู้ใช้หนัก) จะถูกจัดเส้นทางไปยังรุ่น 5.2; สิ่งนี้ทำให้ระบบอัตโนมัติขั้นสูงและเอาต์พุตคุณภาพสูงเข้าถึงได้สำหรับทีมเล็กโดยไม่ต้องสร้างการผสาน API สำหรับผู้ใช้ที่ไม่ใช่สายเทคนิคที่ต้องการสรุปเอกสารหรือสร้างสไลด์ที่ดีขึ้น GPT-5.2 ให้คุณค่าเชิงปฏิบัติที่เห็นผล
ข้อสังเกตเชิงปฏิบัติสำหรับนักพัฒนาและผู้ปฏิบัติการ
คุณสมบัติ API ที่ควรจับตา
- ระดับ
reasoning.effort(เช่นmedium,high,xhigh) ให้คุณบอกโมเดลว่าจะใช้คอมพิวต์กับการให้เหตุผลภายในมากแค่ไหน ใช้เพื่อแลกเวลาแฝงกับความแม่นยำรายคำขอ - Context compaction: API มีเครื่องมือบีบอัดและอัดแน่นประวัติ เพื่อคงไว้ซึ่งเนื้อหาที่เกี่ยวข้องจริงสำหรับการสนทนายาว นี่สำคัญเมื่อคุณต้องคุมการใช้โทเคนให้จัดการได้
- Tool scaffolding & allowed-tools controls: ระบบผลิตจริงควรกำหนด whitelist เครื่องมือที่โมเดลเรียกได้ และล็อกการเรียกเครื่องมือเพื่อการตรวจสอบย้อนหลัง
เคล็ดลับควบคุมต้นทุน
- แคช embedding ของเอกสารที่ใช้บ่อย และใช้อินพุตที่แคช (ซึ่งได้ส่วนลดมาก) สำหรับคำถามซ้ำบนคอร์ปัสเดียวกัน ราคาแพลตฟอร์มของ OpenAI มีส่วนลดอย่างมีนัยสำหรับอินพุตที่แคช
- จัดเส้นทางคำถามสำรวจ/มูลค่าต่ำไปที่ Instant และเก็บ Thinking/Pro สำหรับงานแบตช์หรือรอบสุดท้าย
- ประมาณการการใช้โทเคน (ขาเข้า + ขาออก) อย่างรอบคอบเมื่อวางแผนงบ API เพราะผลลัพธ์ยาวจะคูณต้นทุน
บทสรุป — คุณควรอัปเกรดเป็น GPT-5.2 หรือไม่?
หากงานของคุณพึ่งพาการให้เหตุผลบนเอกสารยาว การสังเคราะห์ข้ามเอกสาร การตีความมัลติโหมด (ภาพ + ข้อความ) หรือการสร้างเอเจนต์ที่เรียกใช้เครื่องมือ GPT-5.2 คือการอัปเกรดที่ชัดเจน: เพิ่มความแม่นยำเชิงปฏิบัติและลดงานผสานรวมด้วยมือ หากคุณเน้นแชตบอตปริมาณมาก เวลาแฝงต่ำ หรือมีข้อจำกัดงบประมาณ รุ่น Instant (หรือโมเดลก่อนหน้า) อาจยังเป็นตัวเลือกที่เหมาะ
GPT-5.2 แสดงการเปลี่ยนผ่านจาก “แชตที่ดีขึ้น” ไปสู่ “ผู้ช่วยมืออาชีพที่ดีกว่า”: คอมพิวต์มากขึ้น ความสามารถมากขึ้น และชั้นราคาที่สูงขึ้น — แต่ก็มาพร้อมการเพิ่มผลิตภาพจริงสำหรับทีมที่ใช้ประโยชน์จากบริบทยาวที่เชื่อถือได้ คณิตศาสตร์/การให้เหตุผลที่พัฒนาขึ้น ความเข้าใจภาพ และการดำเนินงานเครื่องมือเชิงเอเจนต์
เริ่มต้นใช้งานได้เลย สำรวจโมเดล GPT-5.2 (GPT-5.2;GPT-5.2 pro, GPT-5.2 chat ) ใน Playground และดู API guide สำหรับคำแนะนำโดยละเอียด ก่อนเข้าใช้งาน โปรดตรวจสอบว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับ API key แล้ว CometAPI มีราคาต่ำกว่าราคาทางการอย่างมากเพื่อช่วยให้คุณผสานรวมได้ง่ายขึ้น
พร้อมลุยหรือยัง?→ ทดลองใช้ฟรี gpt-5.2 models !